
HiveHealth – open source Bienenstockwaage
Für die Hochschule haben wir eine Open Source Bienenstockwaage und eine Beute zum selber-bauen entwickelt. Die Waage besteht aus einem HX711 mit vier Halbbrücken DMS 50kg Wägezellen. Herzstück ist ein ESP8266. Dieser sendet die Messdaten per MQTT an einen Server. Dazu kann entweder WLAN oder LoRa genutzt werden. Auf dem Server läuft eine InfluxDB, der MQTT Broker Mosquitto, Telegraf sowie Grafana.
Für das Projekt könnt ihr entweder eine vorhandene Beute aufrüsten oder euch direkt nach unseren Plänen eine eigene Bauen. Wir haben zusammen mit einem Imker nach einer Bienenfreundlichen Bauform gesucht, die möglichst nah an der natürlichen Bauform in der „Wildnis“ angelehnt ist. An der Hochschule verfolgen wir aber nicht unbedingt das Ziel den Honig zu ernten.
Warum noch eine open-source Bienenstockwaage?
Wir hatten das Ziel ein Set mit möglichst geringen Investitionskosten zusammen zu stellen und die Einrichtung so einfach wie möglich zu machen, damit auch Imker, die keine Technik-Freunde sind, die Chance haben das Projekt umzusetzen.
Quicklinks
Die Beute
t.b.a.
Die Waage
Rund um den ESP8266 (in unserem Fall ein Wemos D1 Mini) haben wir eine kleine Einheit entwickelt, die eure Bienenstöcke überwachen kann. Hier ist die Teileliste:
- ESP8266 z.B. Wemos D1 Mini
- DHT 22
- HX711
- 4x Halbbrücke Wägezelle
- LoRa Sender (optional)
- 4x Solarzellen 0,5Wp
- Laderegler z.B. TP
- 2x 18650 Akkuzelle
- Wasserfestes Gehäuse
Die Bienenstockwaage kann gerne und relativ einfach mit weiteren Sensoren ergänzt werden. Wir planen derzeit noch an einem Mikrophon.
Beutentyp
Zunächst müssen wir den Beutentyp bestimmen damit wir den Rahmen für die Wägezellen entsprechend aufbauen können. In Emden nutzen wir eine Beute der Bauart XYZ. Hinter jedem Beutentyp ist eine PDF für einen Vorschlag für die Maße der Wagengrundplatte.
- Typ A
- Typ B
- TBA
Die Wägezellen
Es gibt zum einen verschiedene Bauarten von DMS-Wägezellen. Wir setzten auf 4 x 50kg Halb-Brücken Wägezellen, da diese kostengünstig zu erwerben sind und für eine Stockwaage hinreichend genaue Ergebnisse liefern. Diese Wägezellen gibt es aber auch noch einmal in verschiedenen Bauformen. Wir haben versucht alle Bauformen zu finden und jeweils eine entsprechende Halterung zu konstruieren.



Die .STL Dateien zum Drucken bzw. die DXF Daten zum Lasern/Fräsen für diese Abstandshalter gibt es bei Thingiverse. Alternativ kann man sich die hinterlegte PDF auch ausdrucken und den Abstandshalter aus Holz ausschneiden. Wichtig ist nur dass der zum Knicken vorgesehene Bereich des Federkörpers sich frei bewegen kann, damit der Dehnungsmessstreifen seine Arbeit verrichten kann.
[wp-3dtvl model_file=“https://daniel-strohbach.de/wp-content/uploads/2020/12/Halterung_Waegezelle.stl“][/wp-3dtvl].
Funktionsweise
Im DMS (Dehnungsmessstreifen) sind mäanderförmige Leiterbahnen (also im zick-zack, wie bei der Fußbodenheizung) in einer kleinen Folie. Wenn der Federkörper sich verformt, verformt sich auch der Dehnungsmessstreifen. Die Leiterbahnen rücken voneinander weg oder näher zusammen (je nach Biegerichtung) und so ändert sich der innere Widerstand des DMS. Diese Veränderung findet im mV (Millivolt) Bereich statt. Aus diesem Grund brauchen wir auch einen Verstärker – den HX711. Damit wir überhaupt eine Spannungsänderung erkennen können schalten wir die vier Wägezellen zu einer sogenannten Wheatstoneschen Messbrücke zusammen.
Temperaturemfpindlich
Da der Federkörper sich bei Wärme ausdehnt, hat die Temperatur natürlich auch Einfluss auf das Messergebnis. Diese versuchen wir rechnerisch in der Software auszugleichen.
Die Wägezellen werden jeweils in einer 3D-gedruckten Halterung (alternativ geht natürlich auch aus ausgesägten Plättchen) an die vorgesehene Position angebracht und müssen wie folgt verkabelt werden.
Kabelschema erstellen
HX711
Der HX711 ist ein Analog-Digital-Wandler. Er misst die Spannungsabweichung der Wägezelle und überträgt sie in ein digitales Format. Dieser Chip hat eine Auflösung von 24 Bit, das entspricht 16.777.216 Stufen. Dieser AD-Wandler funktioniert mit allen Typen von DMS-Wägezellen.
DHT22
Der DHT22 ist ein kombinierter Feuchtigkeit und Temperatursensor. Damit er von den Bienen nicht zugebaut wird, sollte man einen kleinen Schutzraum um ihn herum konstruieren. Ansonsten kann er beliebig in der Beute platziert werden. GGf. macht es sinn zwei DHT Sensoren in der Beute zu platzieren. Eine am Boden und eine unter dem Dach.
Der Server
Als Datenserver nutzen wir einen RaspberryPi 3B+. Dieser kleine Rechner ist zum einen Preisgünstig und kann leicht angeschafft werden. Nicht jeder Imker möchte sich für mehrere 100€ einen eigenen Server anschaffen. Alternativ könnte man natürlich auch einen virtuellen Webserver mieten oder eine Diskstation nutzen.
- RaspberryPi 3B+
- RaspberryPi Netzteil
- SD-Karte
- Gehäuse (optional)
- LoRa Gateway (optional)
RaspberryPi
Zunächst laden wir uns die aktuelle Version vom RaspianOS herunter. Diese finden wir auf https://www.raspberrypi.org/software/operating-systems/. Da wir für diese Anwendung kein GUI brauchen, reicht die Lite Version vollkommen aus.
Außerdem brauchen wir Balena Etcher. Mit Etcher können wir das heruntergelandene Image auf die SD-Karte flashen.
Für Raspi-Noobs: Es reicht nicht einfach die Zip auf die SD-Karte zu kopieren. Wir müssen das Betriebssystem sozusagen auf der SD-Karte installieren. Daher spricht man hier von flashen.
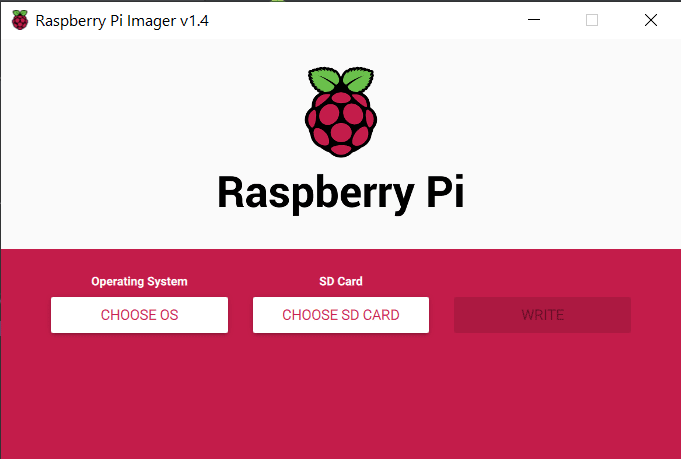
Update: RaspberryPi Imager
Anscheinend hat RaspberryPi ein eigenes Tool zum flashen der SD-Karte herausgebracht. Dieses findet man <hier/>.
Es lässt sich im Prinzip genau wie Etcher nutzen, nur das die entsprechenden Images erst heruntergeladen werden, wenn man es ausgewählt hat. So hat man immer die aktuellste Version. Find ich ganz gut.
Nachdem wir das OS (Operating System) auf die SD-Karte geflasht haben, wollen wir noch schnell die WLAN-Daten und die SSH Verbindung ermöglichen. Dazu öffnen wir einfach die SD-Karte im Explorer und erzeugen eine neue Text-Datei (.txt). Das geht in dem man einen Rechtklick in das freie Feld macht, und im Kontextmenü auf Neu – Textdokument klickt. Falls die frisch geflashte SD-Karte nicht als Datenlaufwerk erkannt wird, steckt sie einmal aus und wieder ein.
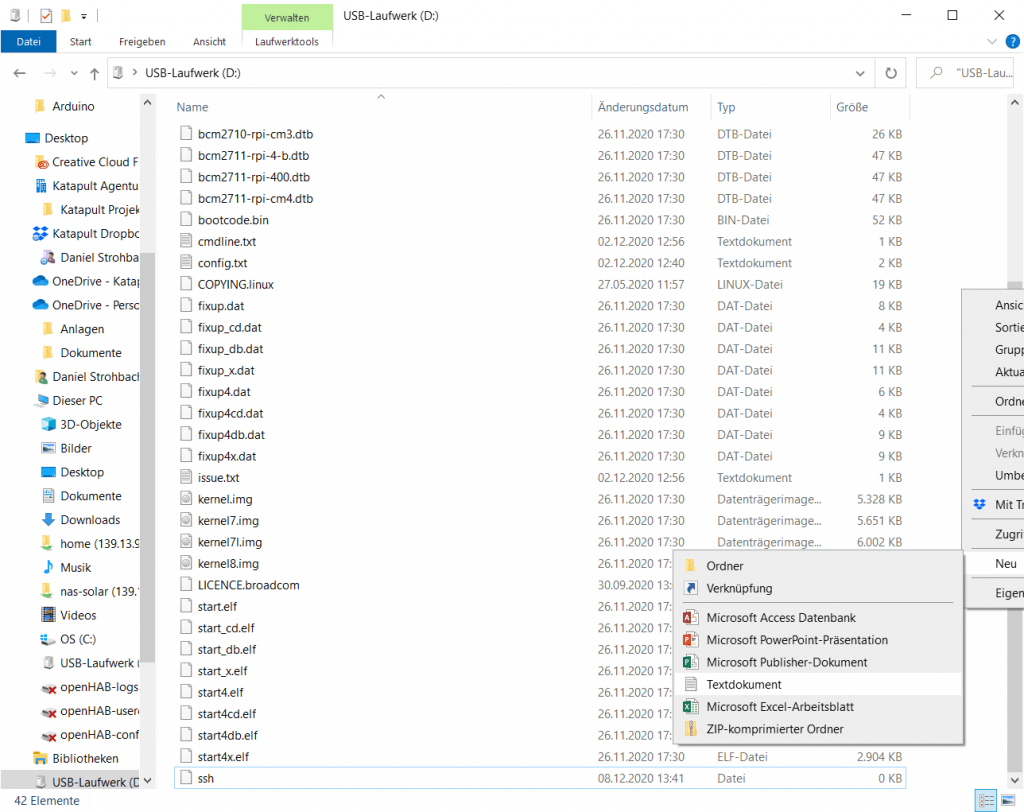
Die Datei nennen wir ssh und löschen die Dateiendung .txt. Es wird eine Warnmeldung auftauchen, die können wir aber ignorieren. Falls ihr eure Dateiendungen ausgeblendet habt, solltet ihr diese Anzeigen lassen. (Irgendwo in der Systemsteuerung).
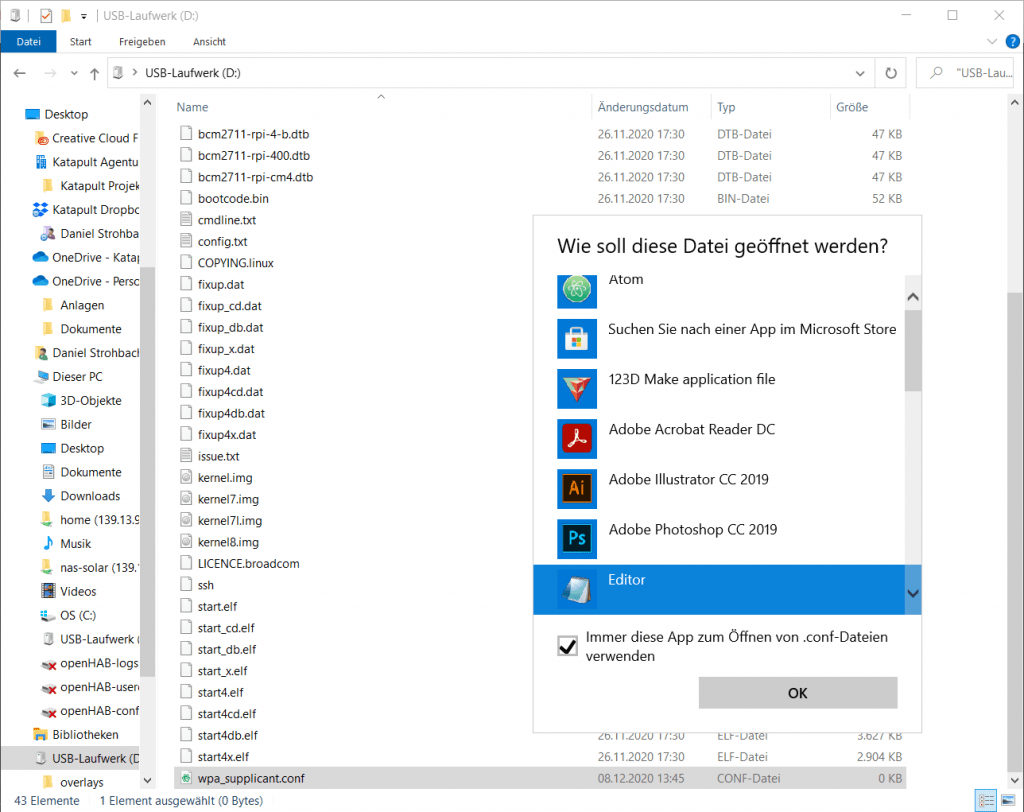
Als nächstes erzeugen wir eine neue .txt Datei. Dieses mal benennen wir sie in wpa_supplicant.conf um. Also die Dateiendung ist nun .conf anstatt .txt. Wenn wir den RaspberryPi dann booten, wird sie in das korrekte Verzeichnis kopiert.
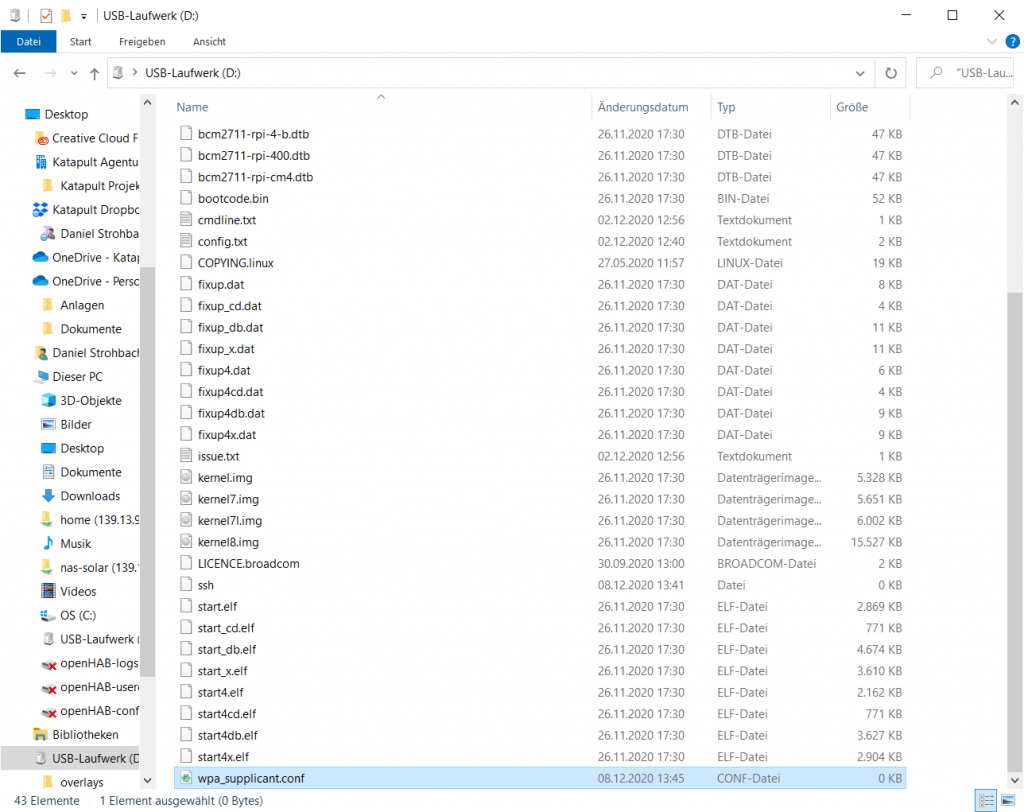
In diese wpa_supplicant.conf müssen wir noch etwas eintragen, also öffnen wir sie mit einem Doppelklick. Falls Windows euch fragt, womit diese Datei geöffnet werden soll, könnt ihr ruhig den Editor auswählen. Dann tragen wir folgendes ein:
country=DE # Your 2-digit country code
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
network={
ssid="YOUR_NETWORK_NAME"
psk="YOUR_PASSWORD"
key_mgmt=WPA-PSK
}
Wenn wir alles soweit vorbereitet haben, stecken wir die (micro) SD-Karte in den RaspberryPi und können ihn an das Netzteil anschließen. Wenn alles korrekt ausgeführt wurde, sollte der kleine Rechner nun booten, was man an einer wild blinkenden Grüngelben LED erkennen kann. Ausreichende Energieversorgung erkennt man an der Roten LED. Achtet darauf, dass euer Netzteil genügen Saft (2A) liefert.
Gehäuse (Optional)
Ich habe noch ein schönes Gehäuse für dieses Projekt besorgt, das ist natürlich nicht zwingend Notwendig. Ich hab dieses <hier/>
SSH Verbindung
Als nächstes müssen wir die IP des RaspberryPi herausfinden. Dazu gibt es zwei Möglichkeiten. Entweder nutzen wir einen IP-Scanner oder wir loggen uns ins Interface unseres Routers ein. Wenn ihr in einem Hochschulnetzwerk seid, bitte sprecht vorher mit dem Rechenzentrum. Diese mögen die Nutzung von IP-Scannern im Netzwerk nicht so gern. Wenn wir die IP herausgefunden haben, nutzen wir die Windows Console bzw. das Windows Terminal oder Putty.
Dazu drücken wir die Windows Taste und tippen direkt cmd und bestätigen mit Enter. Nun öffnet sich die Console.
Hier geben wir nun den Befehl ein, wobei ihr die IP entsprechend anpassen müsst. Pi ist der Standard-Benutzername und kann so bleiben:
ssh pi@192.168.0.xxxNun werden wir gebeten die Adresse des Pi zu speichern, damit keine Man in the Middle Attacke ausgeführt werden kann. Machen wir gerne und tippen yes ein. Dann möchte man von uns, das Passwort einzugeben. Das sollte nun dem RaspberryPi Standard-Password entsrpechen:
raspberry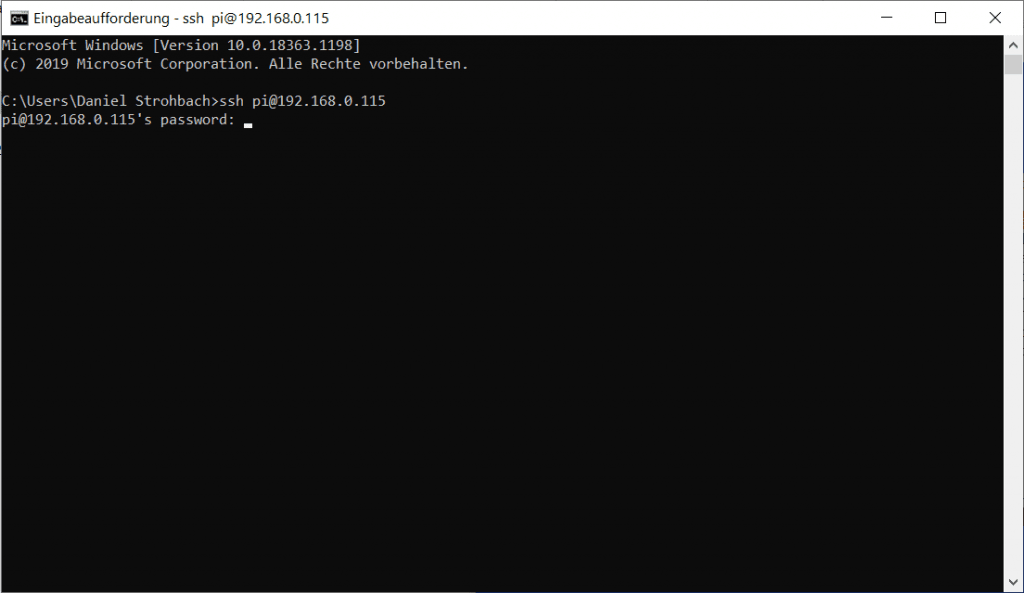
Nun sind wir mit einer SSH Verbindung mit dem Raspi-System verbunden. Als nächstes folgt der Befehl:
sudo raspi-configDieser öffnet folgendes Fenster:
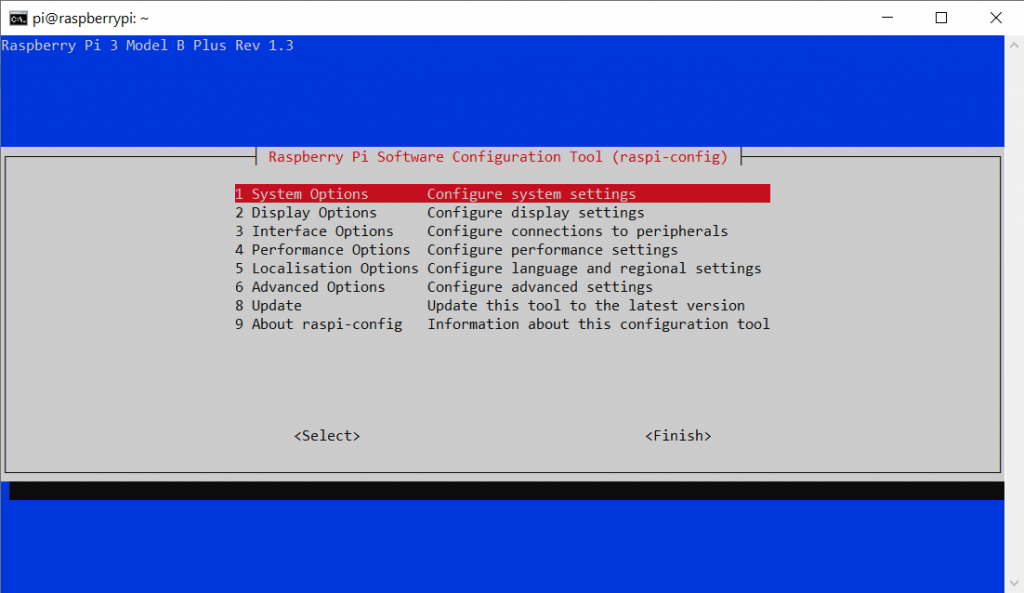
Wir können mit den Pfeil-Tasten und Enter navigieren. Wir drücken direkt auf Punkt 1 Enter und gehen daraufhin auf Punkt S3 um das Standard-Kennwort auf ein eigenes zu Wechseln.
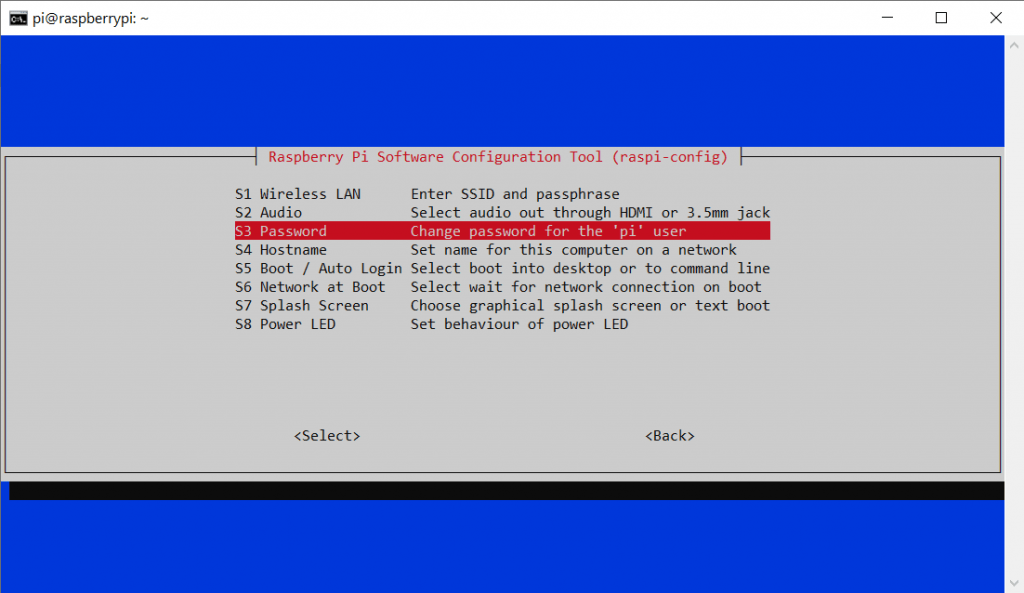
Dann suchen wir uns ein schönes Passwort aus und tippen es Zweimal ein. Wenn es korrekt war können wir uns zukünftig nur noch mit dem neuen Passwort über SSH einloggen. Danach können wir die Config erstmal verlassen. Mit der Pfeiltaste nach rechts kommen wir auf den Button Finish. Wenn wir nun gefragt werden, ob wir den Raspberry neu starten möchten, bestätigen wir das. Die SSH Verbindung wird geschlossen und wir müssen einen Moment warten, bis der Raspi wieder online ist. Dann loggen wir uns mit dem neuen Kennwort ein und geben die folgenden Befehle ein:
sudo get-apt update
sudo get-apt upgradeDamit bringen wir RaspibanOS auf den neuesten Stand und können danach anfangen, die benötigten Pakete zu installieren.
InfluxDB
Damit wir unsere Sensordaten später schön Visualisieren können, brauchen wir eine sogenannte Time-Series Database. Also eine Datenbank die Daten mit Zeitstempeln speichert. InfluxDB ist genau für diese Anwendung entwickelt worden und ein beliebtes OpenSource Projekt. Also installieren wir diese mit dem folgenden Befehl:
sudo apt-get install influxdbTipp: Wenn ihr Befehle hier herauskopieren und in das Terminal einfügen wollt, könnt ihr das mit einem Rechtsklick in das Terminal machen.
Sudo steht dabei für „Super User Do“ und entspricht in etwa dem „Als Administrator ausführen“ aus der Windows-Welt. apt referenziert das Linux Paket Verzeichnis. Install kann man sich denken. Dieser Befehl durchsucht also das Paketverzeichnis (auf den Servern der Linux-Leute) nach dem richtigen Paket für influxdb und installiert es dann. Ziemlich praktisch oder? Das sollte in etwa so aussehen:
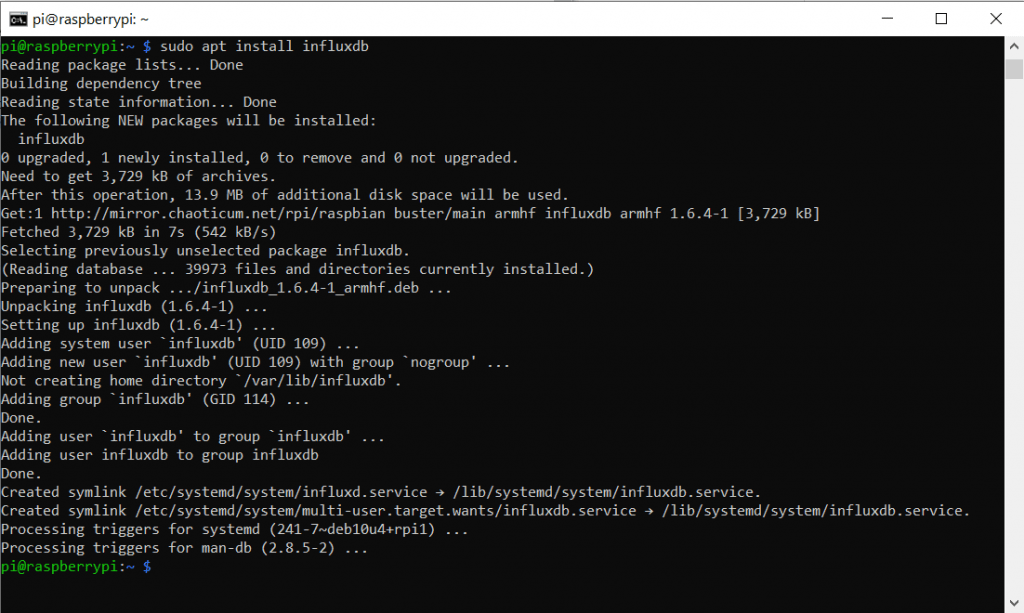
Wie man sieht wurden auch ein paar System-User (neben dem Standard User „Pi“) angelegt.
Zusätzlich brauchen wir noch das Paket für InfluxDB-Clients:
sudo apt install influxdb-client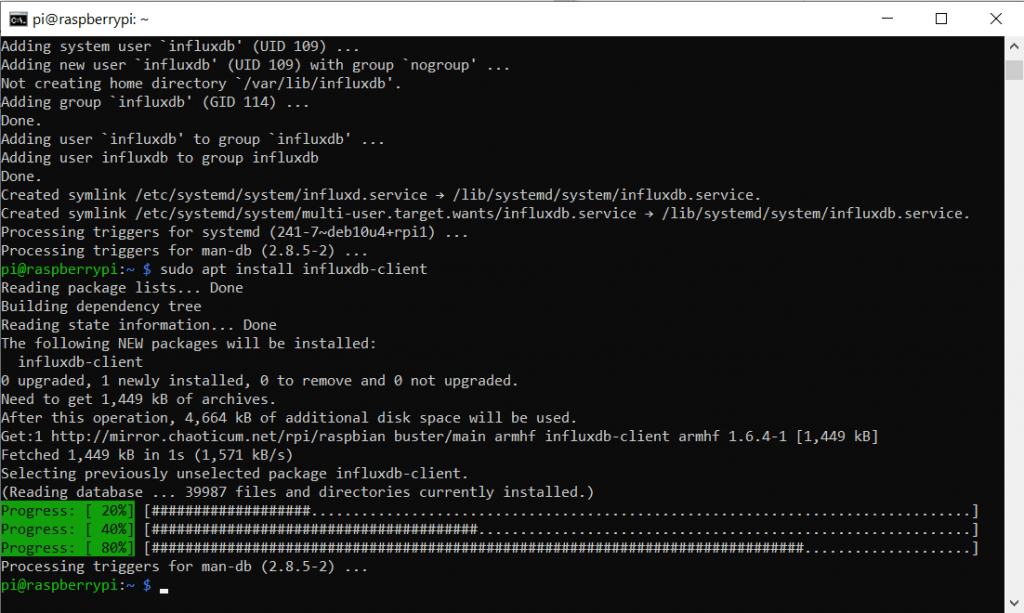
Jetzt können wir die Datenbank-Software starten. Hier spricht man von einem Service. Dieser Befehl lieft nicht sonderlich viel Feedback.
sudo service influxdb start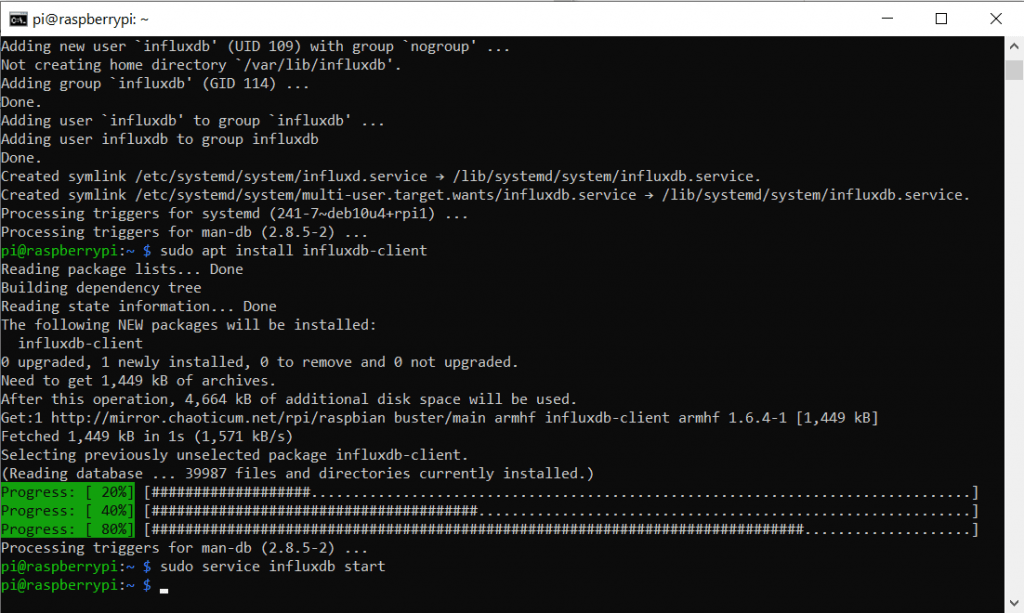
Daher können wir den Service-Status einmal manuell abfragen. Dazu gibt es einen weiteren Befehl:
sudo service influxdb status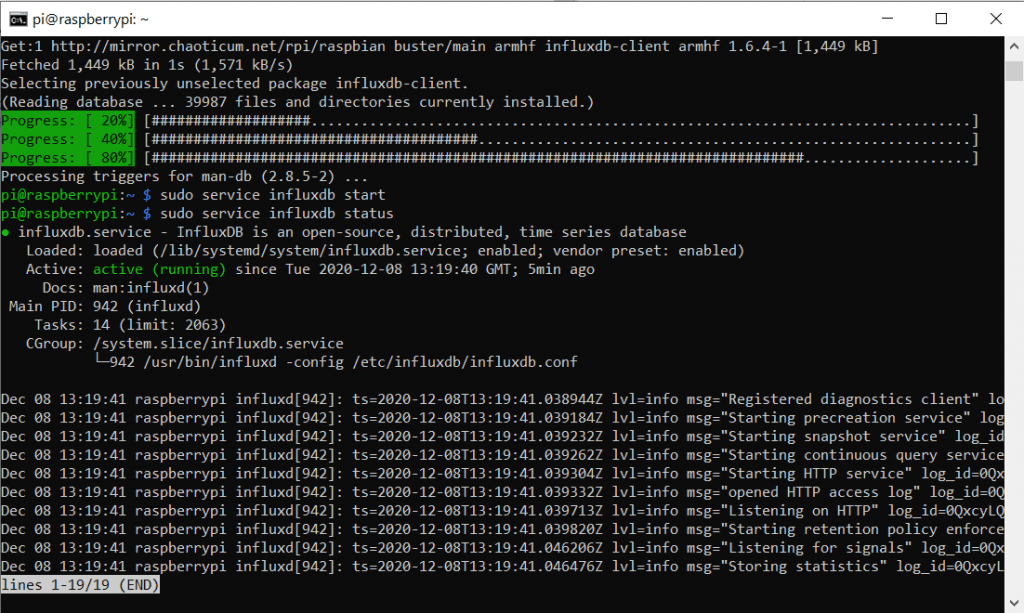
Mit der Tastenkombination Strg + C (nur im Terminal, sonst ist es Kopieren) verlassen wir die Statusabfrage.
Nun wollen wir noch ein paar Änderungen an der InfluxDB Konfiguration vornehmen. Natürlich gibt es einen Text-Befehl dafür:
sudo nano /etc/influxdb/influxdb.conf
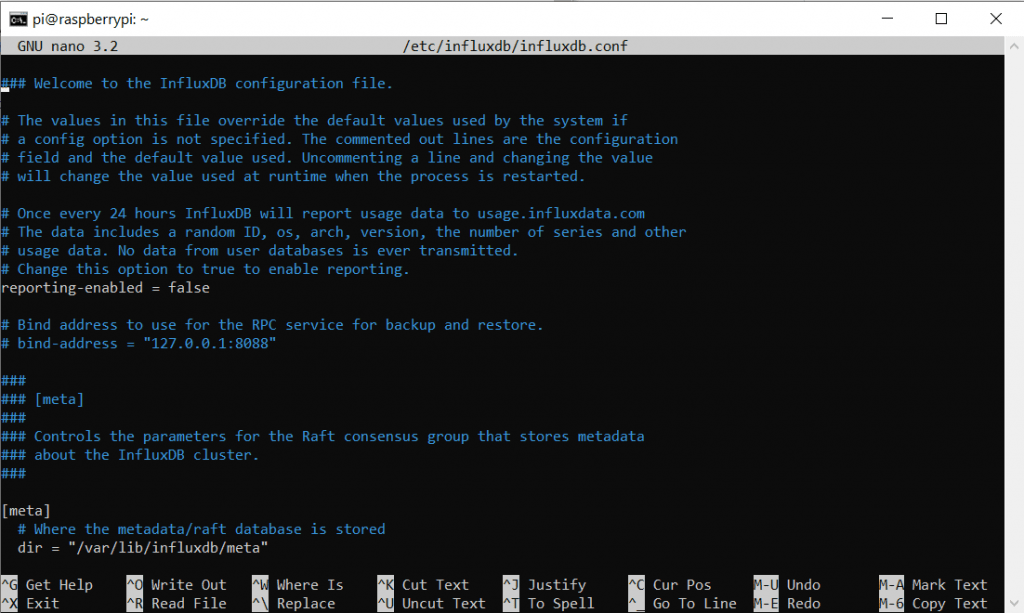
Nano ist ein Consolen-Basierter Text-Editor den wir anweisen, die Conf Datei zu öffnen. So ähnlich wie wir es zu Anfang mit dem Texteditor unter Windows gemacht haben. Hier können wir ebenfalls mit Pfeiltasten Navigieren. Diese .conf Datei ist sehr lang. Wir suchen den Abschnitt mit der Überschrift http und löschen unter der Zeile die Raute # um diese Einstellung zu aktivieren.
Vorher:
# Determines whether HTTP endpoint is enabled.
# enabled = trueNachher:
# Determines whether HTTP endpoint is enabled.
enabled = trueIm Editor sollte es so ausshen:
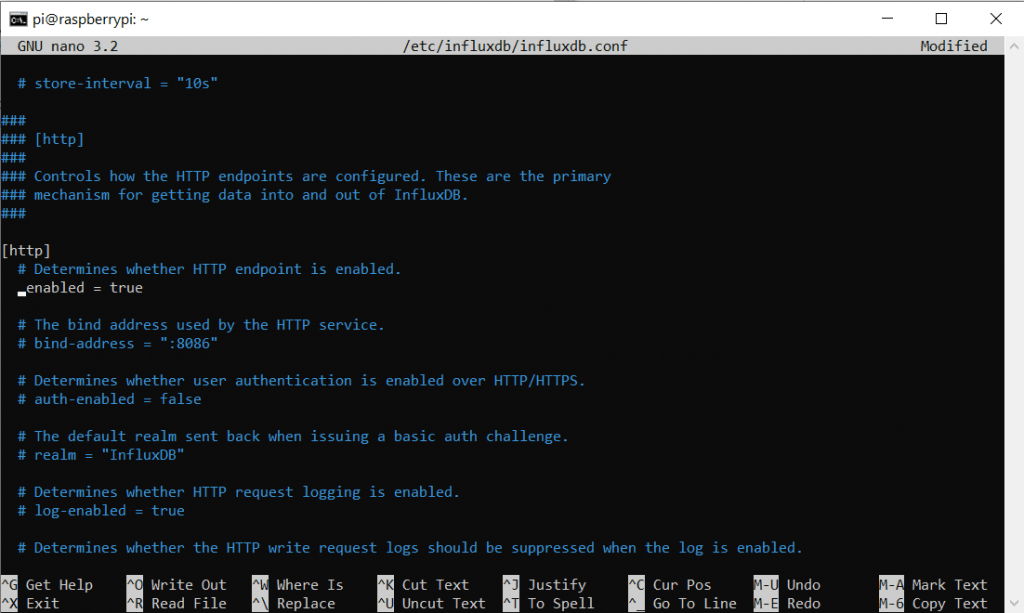
Diese änderung speicher wir mit Strg + O und bestätigen mit Enter. Danach können wir Nano (den Editor) mit Strg + X verlassen. Die Befehle sind auch in der Fußzeile aufgeführt.
Nun sollten wir den Service (Also den Software-Prozess um es mit Windows-Worten zu sagen) neu starten:
sudo service influxdb restartNun betreten wir den Influx-Client bereich um weitere Einstellungen vorzunehmen. Stellt euch vor ihr würdet mit einem GUI (Graphic User Interface) interagieren. Nur halt Textbasiert. Wir starten mit:
influx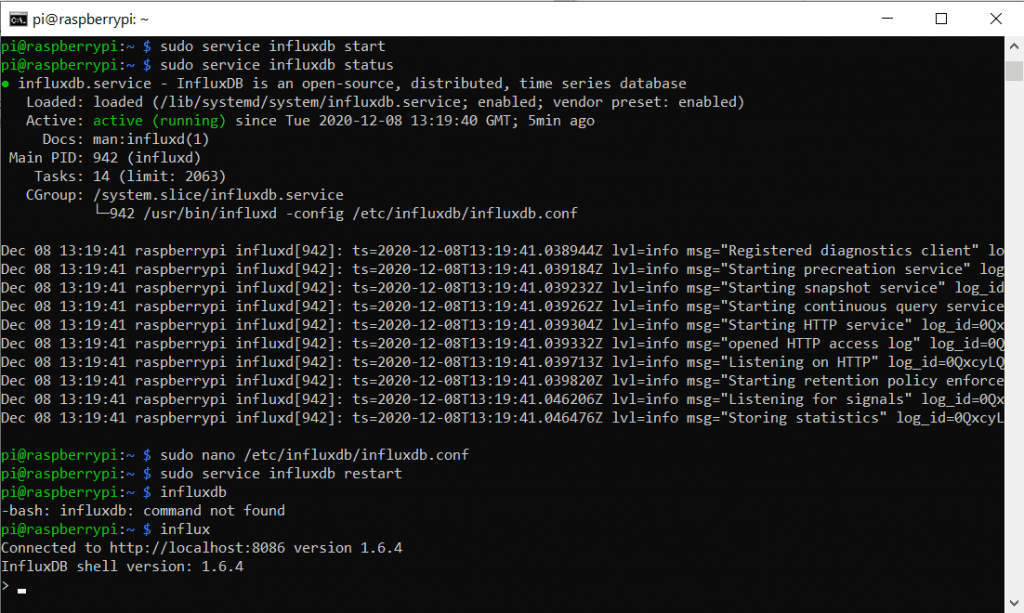
Nun können wir die eigentliche Datenbank anlegen. Das geht mit dem Befehl
create database hivehealthNatürlich könnt ihr die DB beliebig benennen. Danach brauchen wir noch einen User der die Daten in die Datenbank schreiben und lesen darf.
create user telegraf with password 'somesavepassword'
grant all on hivehealth to telegraf
create user grafana with password 'somesafepasswordagain'
grant read on hivehealth to grafanaWir haben den User telegraf angelegt und mit allen rechten (innerhalb influxdb) ausgestattet. Der User Grafana kann nur lesen. Das PW könnte natürlich eine Spur sicherer sein, aber das müsst ihr selbst festlegen. Das war es für uns erstmal mit der InfluxDB Einrichtung. Ich möchte euch aber noch kurz folgende Befehle nahelegen:
Zeigt alle Datenbanken an:
show databasesAls User einloggen:
authDatenreihen ansehen:
show series on <db>Wir verlassen den InfluxDB Bereich mit
exitWer sich weiter mit InfluxDB beschäftigen möchte, kann hier auch den Getting Started Guide lesen.
Zu guter letzt wollen wir den InfluxDB Service bei jedem Booten automatisch mit starten:
sudo systemctl enable influxdbMQTT
MQTT ist eine Art Chat Protokoll für IOT Geräte. Es werden kleine Textnachrichten geformt die wenig Datenrate verbrauchen (somit auch gut für LoRa geeignet sind). Es gibt einen zentralen Broker der alle Nachrichten Empfängt und ggf. an Abonennten (hier Subscriber) weiterleitet. Man kann also Nachrichten auf Kanälen (hier Topics) senden bzw. posten (hier publishen) und ebenso kanäle abonieren (hier subscribe).
Ein beliebter MQTT Broker ist Mosquitto. Genau diesen installieren wir wieder aus dem Linux-Paket verzeichnis mit dem Befehl:
sudo apt install mosquitto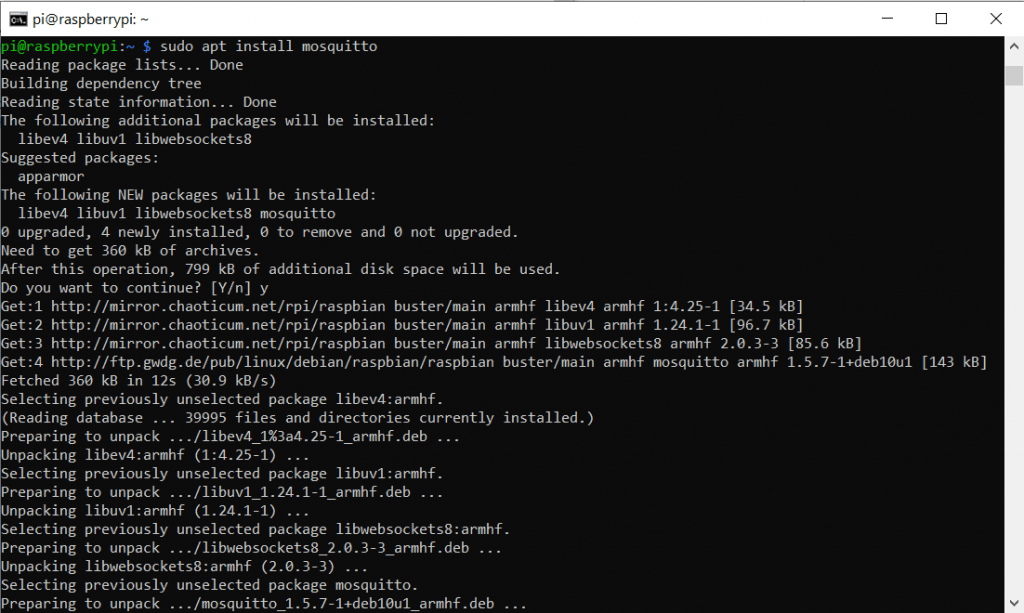
GGf. müsst ihr eine Zwischenfrage nach Speichernutzung mit y bestätigen. Damit wir das nicht müssen können wir auch ein -y am Ende des Befehls einfügen. Auch hier brauchen wir wieder die Client-Pakete und können die -y Funktion direkt testen:
sudo apt install mosquitto-clients -y
Auch hier möchten wir wieder ein paar Anpassungen in der entsprechenden Config-File vornehmen. Dazu nutzen wir wieder den Nano-Editor:
sudo nano /etc/mosquitto/mosquitto.confVorher:
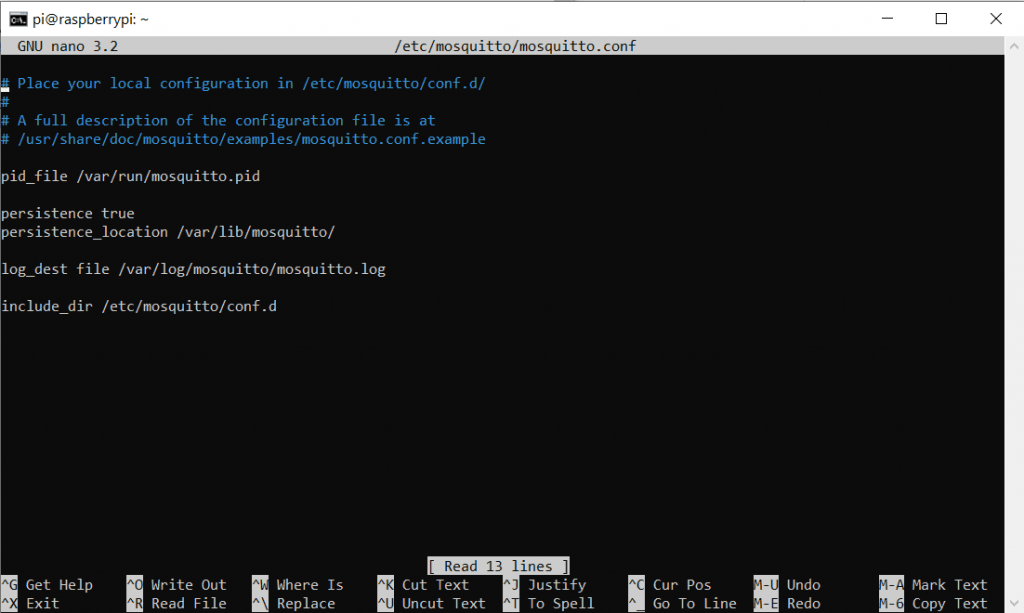
Nachher:
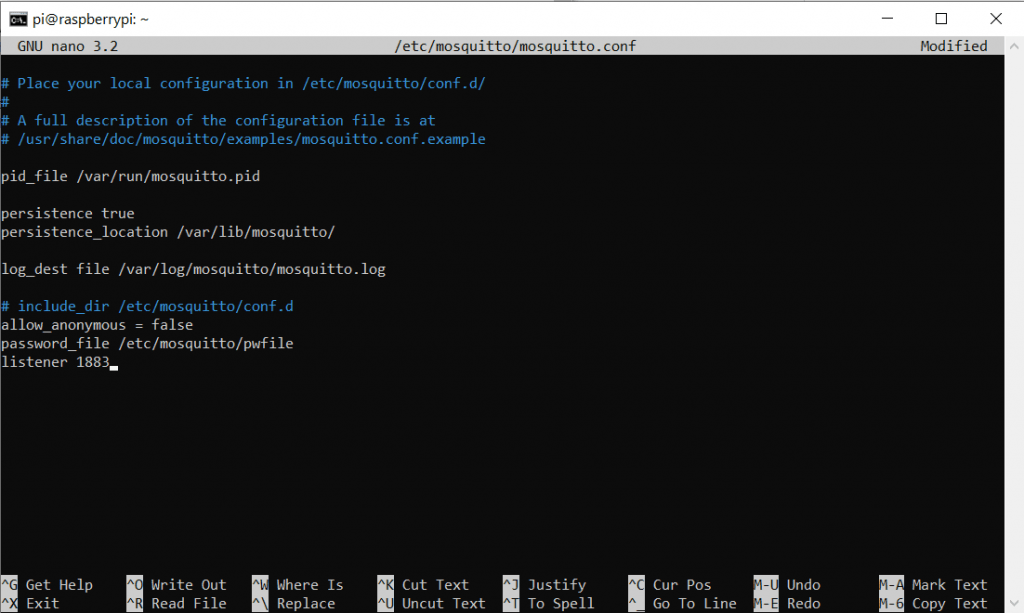
Wir schließen durch die Raute die Zusatzkonfigurationen aus und verbieten anonymen Nutzern die Anmeldung. Außerdem legen wir den Port fest (1883) und sagen der Config dass wir ein PW nutzen wollen. Hier ist der Code zum copy& pasten:
allow_anonymous false
password_file /etc/mosquitto/pwfile
listener 1883Achtung: Im Screenshot ist allow_anonymous = false. Die Zeile ist Falsch!
Dann legen wir diese -Sicherheits-Datei an:
sudo mosquitto_passwd -c /etc/mosquitto/pwfile mqttmqtt steht dabei für den Username. Nun werden wir nach einem PW gefragt, welches wir 2 mal eintippen müssen.
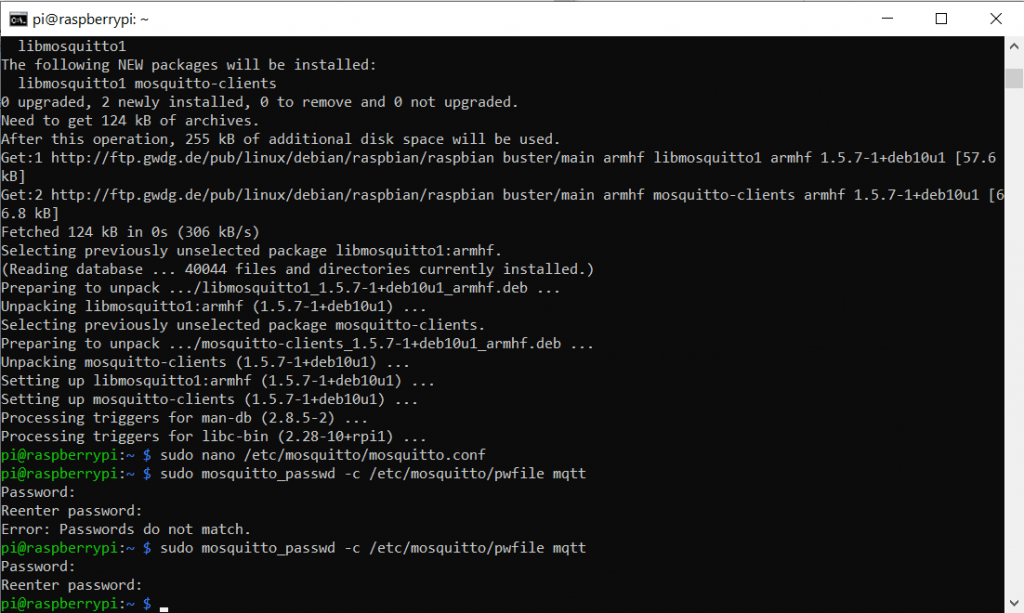
Tipp: Falls ihr euch auch vertippt, könnt ihr mit der Pfeil nach oben Taste den letzten Befehl wieder holen.
Falls ihr den Nutzer löschen wollt:
sudo mosquitto_passwd -d /etc/mosquitto/pwfile username
Gestartet wird der Service wieder mit
sudo service mosquitto startDann können wir noch den Status des Service abfragen um zu prüfen ob alles korrekt läuft:
sudo systemctl status mosquitto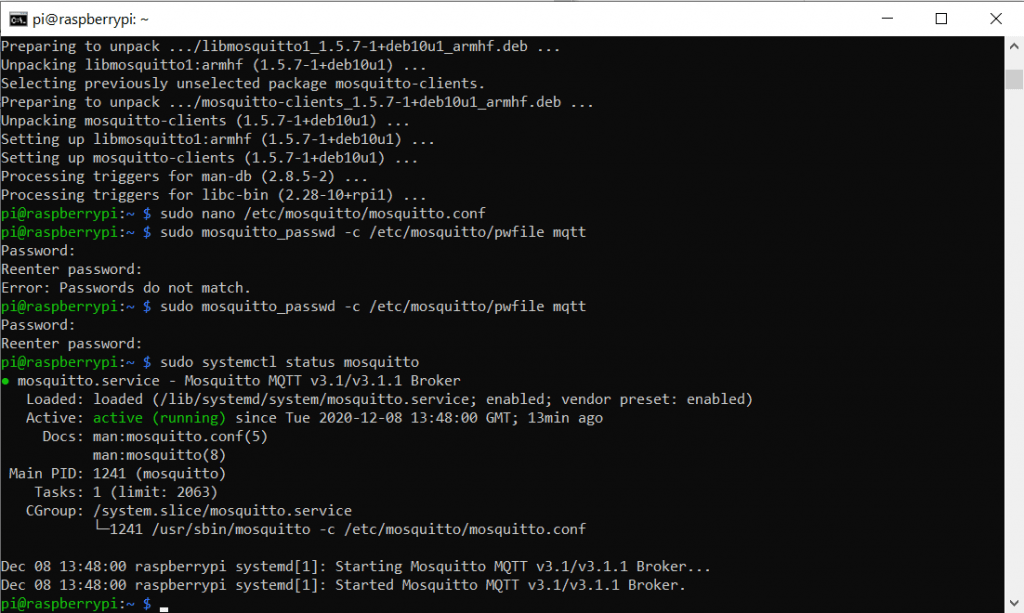
Man kann den Prozess für Mosquitto auch direkt nach dem Booten des Raspberry Pi starten. Dazu nutzen wir den folgenden Befehl:
sudo systemctl enable mosquitto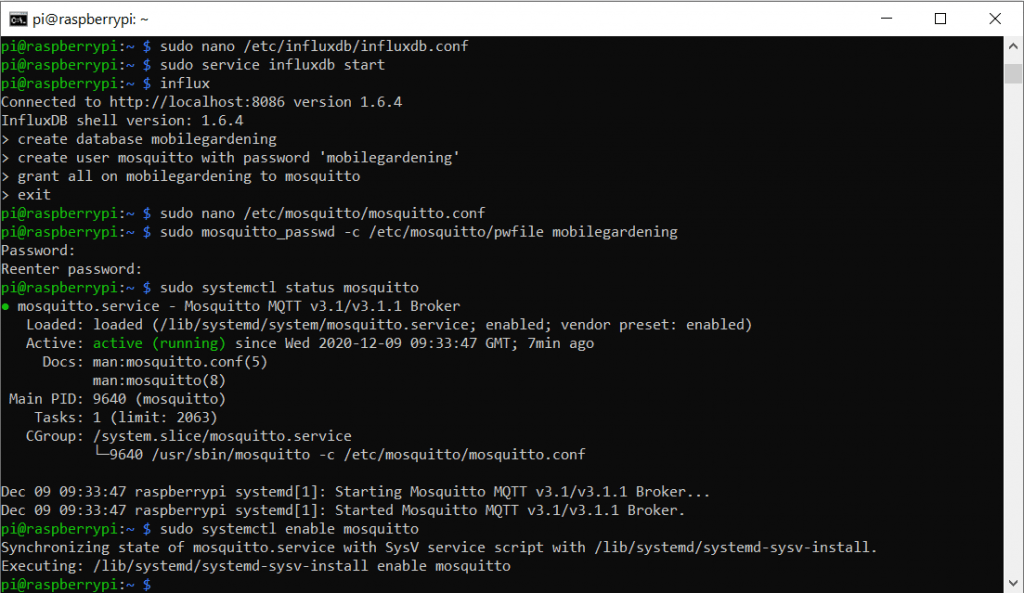
Solltet ihr Mosquitto mal stoppen wollen gibt es entsprechend noch:
sudo systemctl stop mosquitto
Falls der Service nicht startet, habt ihr vermutlich einen Tippfehler in euer Config Datei, oder es liegen fehler in den Lese/Schreibrechten vor. GGf. hilft es mit
sudo apt purge mosquitto mosquitto-clientsdas ganze Paket zu entfernen und dann neu zu installieren. (Kanonen auf Spatzen, i know)
MQTTfx
An dieser Stelle macht es sinn die Funktion von Mosquitto zu testen. Dazu können wir ein Programm namens MQTTfx benutzen. Es gibt noch andere MQTT Helfer, doch finde ich dieses sehr Nutzerfreundlich und möchte es daher gerne Empfehlen (kostenlose Werbung für den Entwickler Jens Deters, weil toll).
Update: Mittlerweile nutze ich MQTT Explorer, da MQTTfx kostenpflichtig geworden ist.
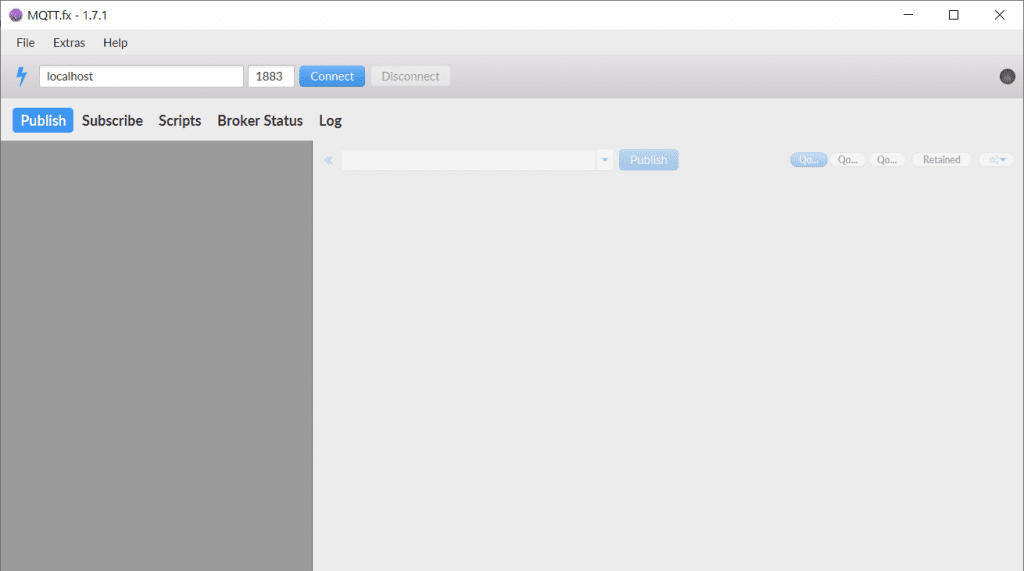
Wir klicken zunächst auf den blauen Blitz und danach auf das neu erschienene Zahnrad. Es sollte sich ein neues Fenster öffnen. Dort können wir unten links auf das blaue Plus Icon klicken um ein neues Profil anzulegen. Das empfiehlt sich, falls ihr irgendwann mehrere MQTT Broker (für weitere coole Bastelprojekte) habt.
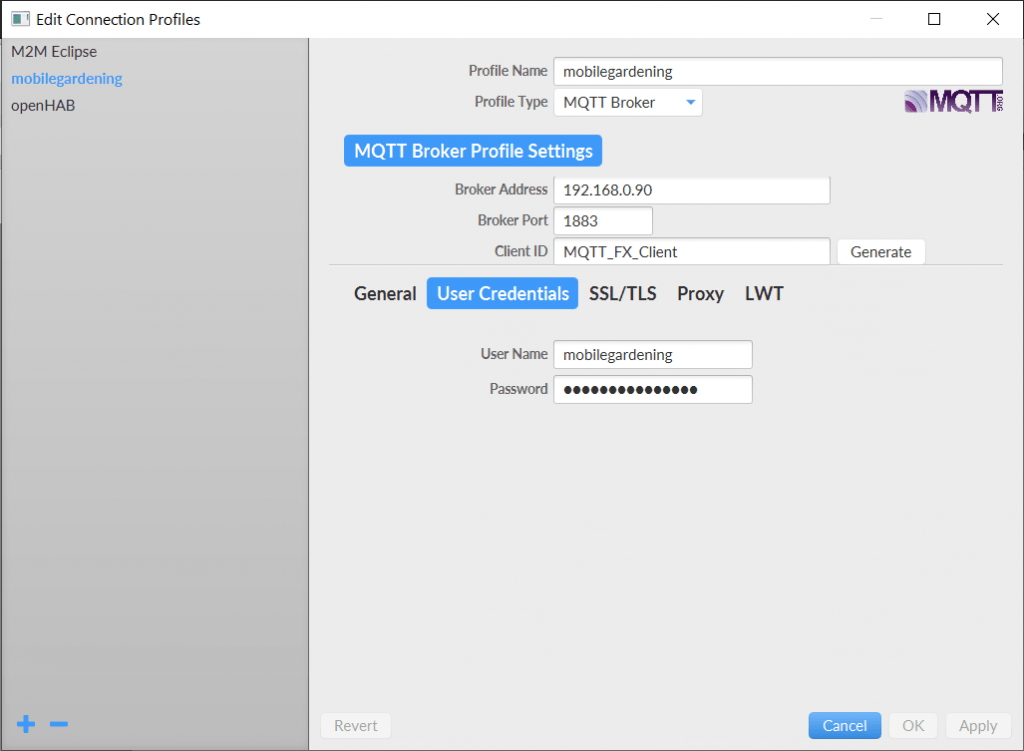
Wir legen einen Namen für das Profil fest. Außerdem müssen wir unsere IP, den Port sowie die LogIn Daten für unseren MQTT Broker hinterlegen. Die Client ID kann so bleiben. Dann können wir auf OK klicken und dann zurück im Hauptfenster auf Connect.
Nun gibt es verschiedene Reiter. Wir können Testweise eine Nachricht über den Bereich publish verfassen und veröffentlichen.
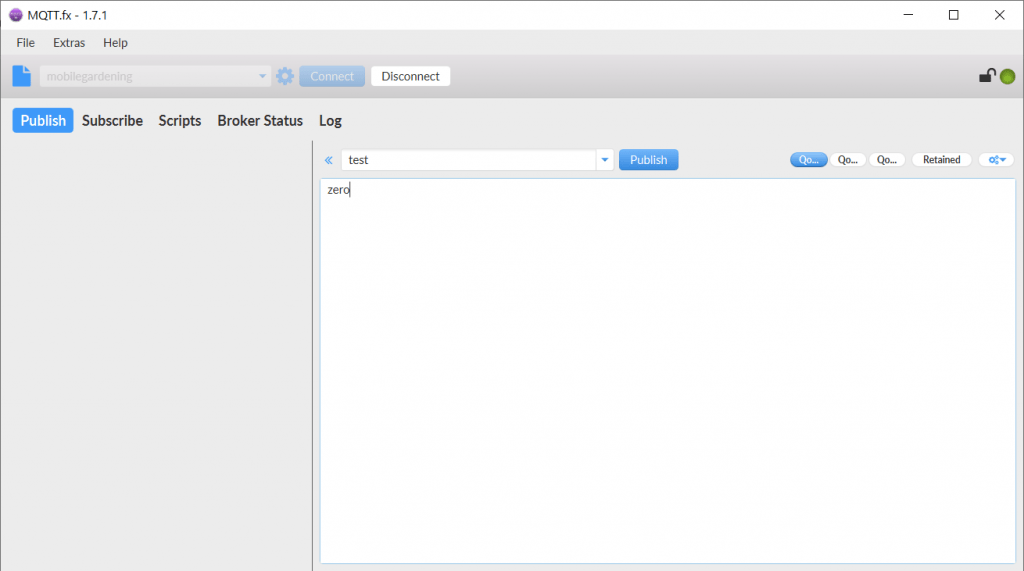
Interessanter für uns ist aber der Bereich Subscribe. Hier gibt es unten Links einen Bereich in dem wir automatisch nach allen verfügbaren Topics schnüffeln können. So kann man alle Signale die der Broker so bekommt und verteilt sehen und auch ggf. auf Eindringlinge oder Fehler in der Schreibweise schließen.
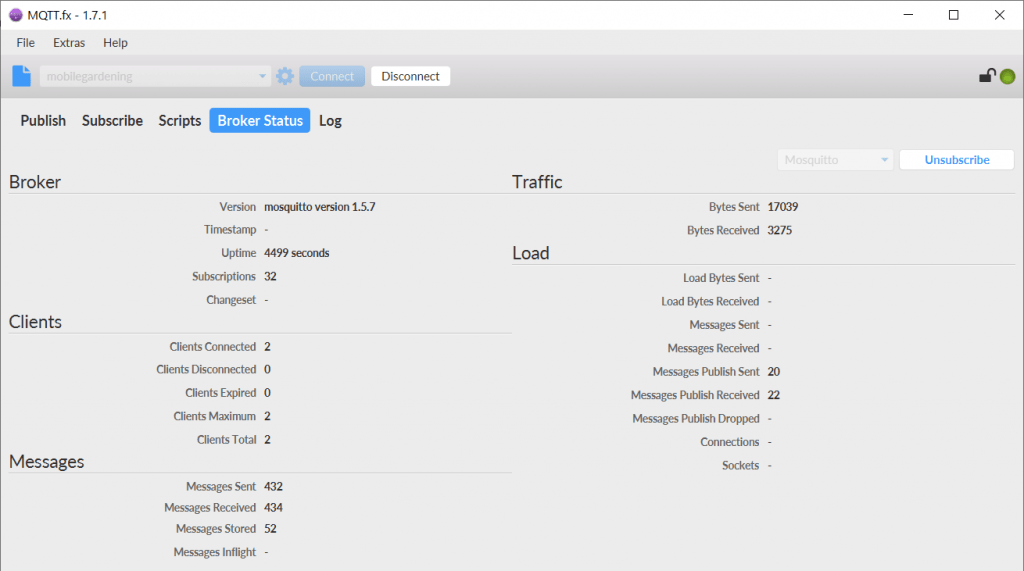
Bei uns wird noch nichts gefunkt. Ein weiterer interessanter Reiter ist der Broker Status. Dort müssen wir zuerst oben Rechts den Broker Typ auswählen (Bei uns Mosquitto) und dann auf Subscribe drücken. Nun sehen wir ein paar Daten über den Broker.
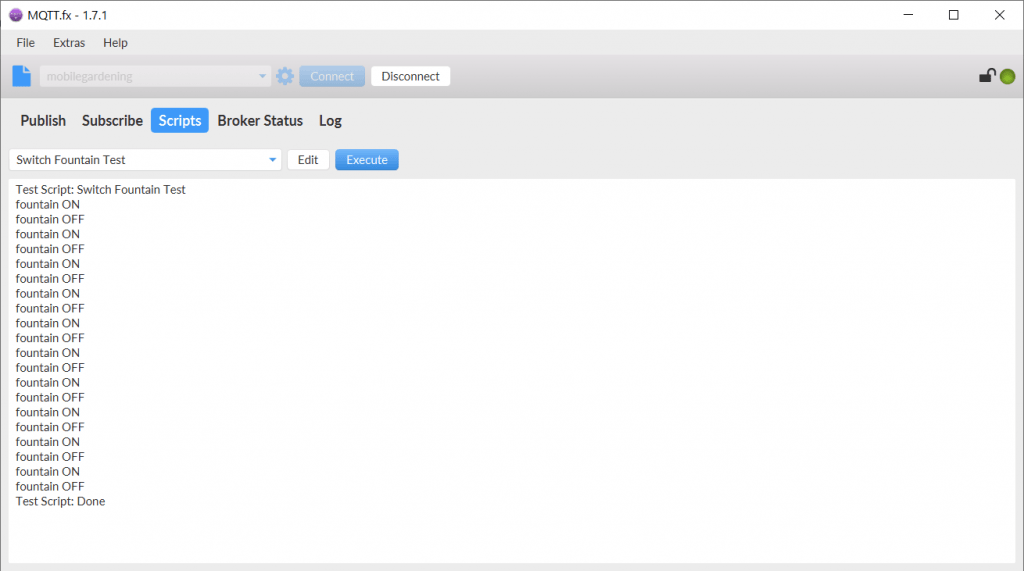
Bei Scripts gibt es ein kleines Testscript, welches ein paar An und Aus Befehle für einen Brunnen simuliert. Wenn wir auf Execute drücken wird es ausgeführt.
Ob das funktioniert hat können wir nun im Reiter Subscribe überprüfen. Wenn wir den Topic-Scanner laufen hatten sollte er das entsprechende Topic gefunden haben:
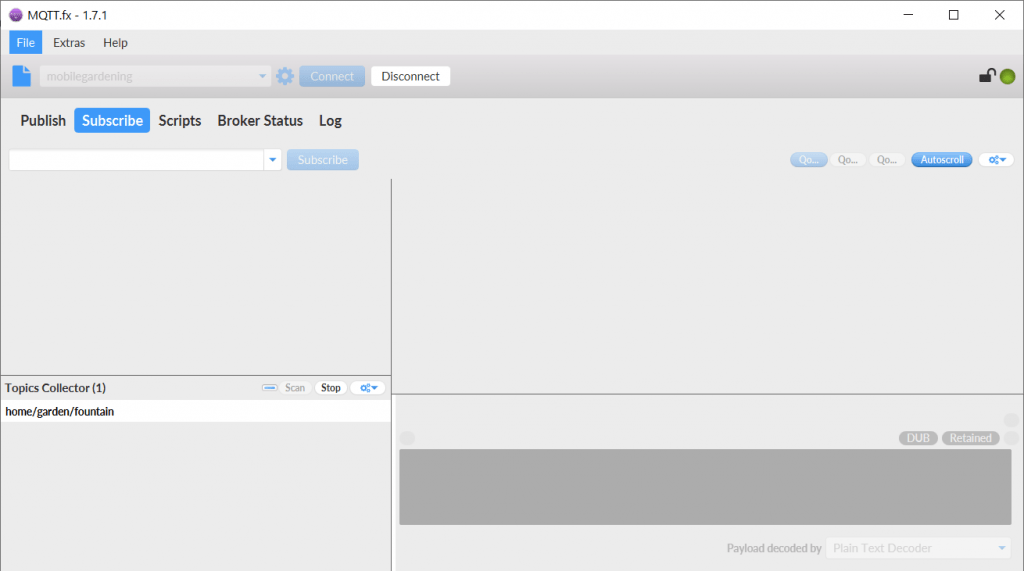
Wen wir darauf einen Doppelklick anwenden abonieren (subscriben) wir das Topic. Danach können wir das Script noch einmal starten und direkt wieder in den Subscribe Reiter wechseln. So können wir Life verfolgen, wie die Nachrichten auftauchen.
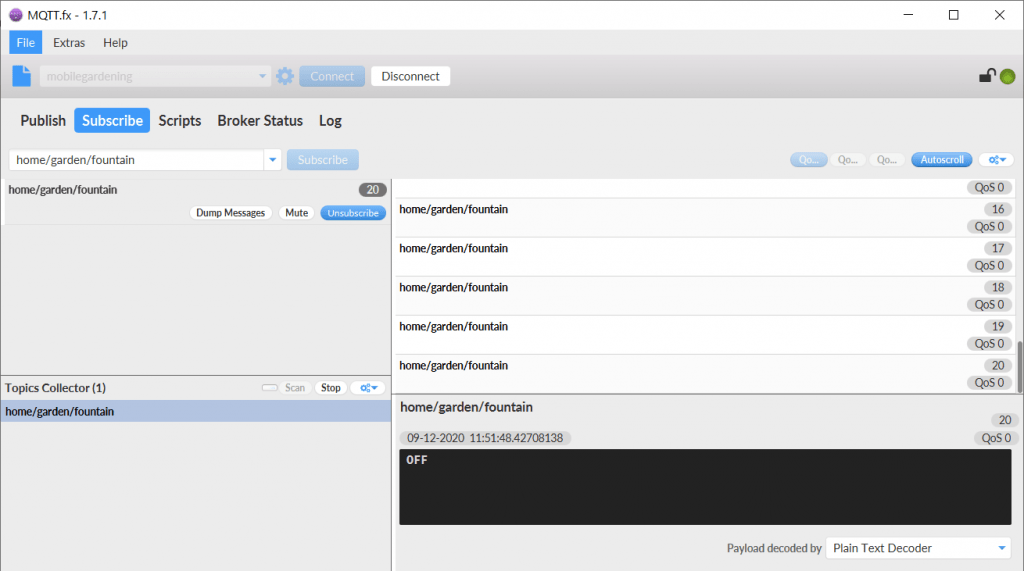
Der MQTT Broker funktioniert also. Soweit so gut. Zeit für frischen Kaffee 😉
MQTT to InfluxDB
Nun müssen wir noch dafür sorgen, dass die Sensordaten, die im Mosquitto landen, auch in die Datenbank abgelegt werden. Dazu kann man entweder ein eigenes PythonScript anlegen oder man nutzt den Dienst Telegraf dafür. Ich gehe hier auf beide Varianten ein.
Telegraf
Telegraf ist ein open-source Server Agent. Er sammelt einfach alles was wir wollen vom MQTT Broker ein und leitet es an die InfluxDB weiter. Mehr Infos zu Telegraf gibt es <hier/>.
Für die installation von Telegraf müssen wir eine neue Paketquelle anlegen. Dazu führen wir einen cURL (client URL) Befehl aus:
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -Mit diesem Befehl fragen wir die URL (den Link) ab. -s unterdrück dabei den Fortschrittsbalken und -L (also kombiniert -sL) prüft ob das Verzeichnis ggf. verschoben wurde und würde dann die Abfrage noch einmal mit der neuen Location ausführen.
Der Abschnitt apt-key add ist ein Teil eines Sicherheitsfeatures unter Linux und fügt dem sogenannten Schlüsselbund einen neuen Key hinzu.
Danach führen wir einen Echo und einen Tee Befehl aus. So speichern wir im Prinzip den String in die Liste am Ende des tee Befehls. So haben wir nun unsere Paketquellen ergänzt.
echo "deb https://repos.influxdata.com/debian stretch stable" | sudo tee /etc/apt/sources.list.d/influxdb.listDann muss man die Paketliste noch aktualisieren, damit die Ergänzung berücksichtigt wird.
sudo apt-get update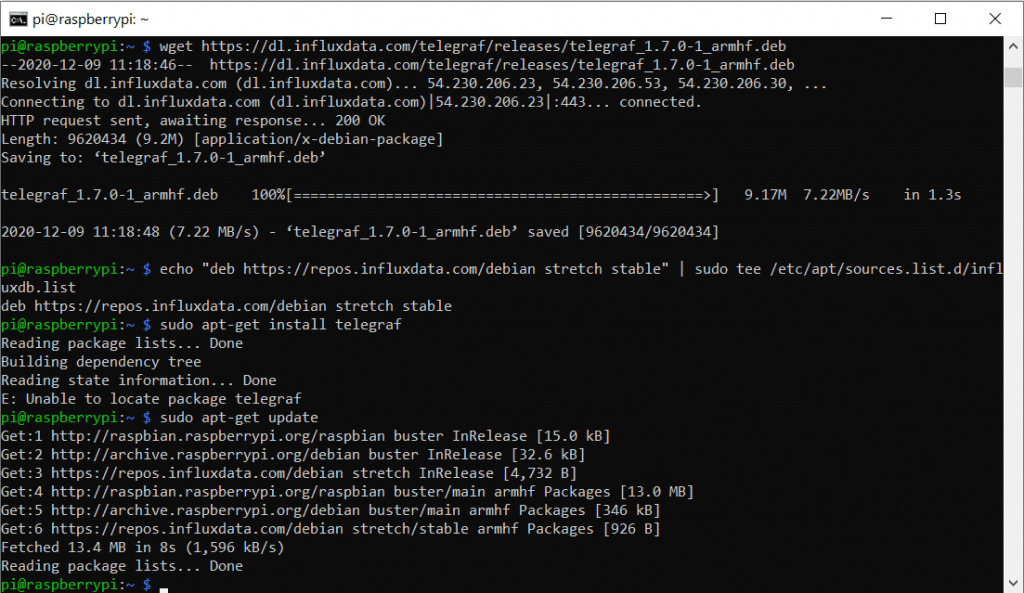
Dann installieren wir das Package für Telegraf
sudo apt-get install telegraf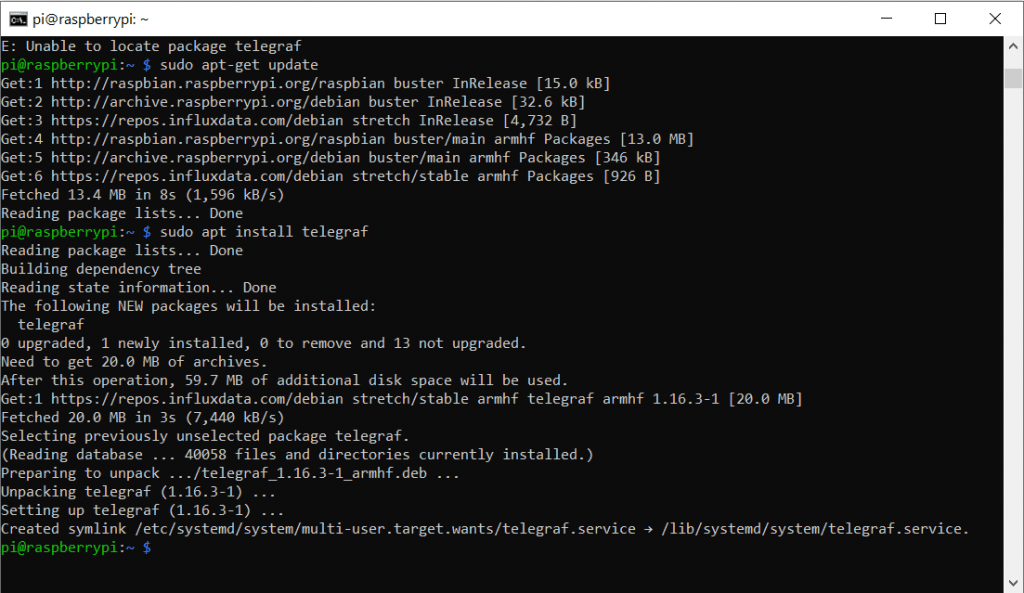
Man kann das Paket auch manuell mit (wget – siehe oberer Screenshot) Herunterladen und installieren, aber dann ist später das Updaten umständlicher. Dann können wir den Service telegraf auch schon starten und dafür sorgen dass es beim Systemstart mit gestartet wird:
sudo service telegraf start
sudo systemctl enable telegrafDen Status kann man wieder mit dem entsprechenden Befehl überprüfen:
sudo systemctl status telegrafNatürlich müssen wir auch hier wieder in der Config-File herumdoktoren: Dazu nehmen wir wieder das Nano-Tool zur Hand:
sudo nano /etc/telegraf/telegraf.confAuch diese Datei ist wieder relativ lang. Wir nutzen erneut die Pfeiltasten um zum Bereich Outputs zu navigieren. Hier ändern wir den Code wie folgt:
Vorher:
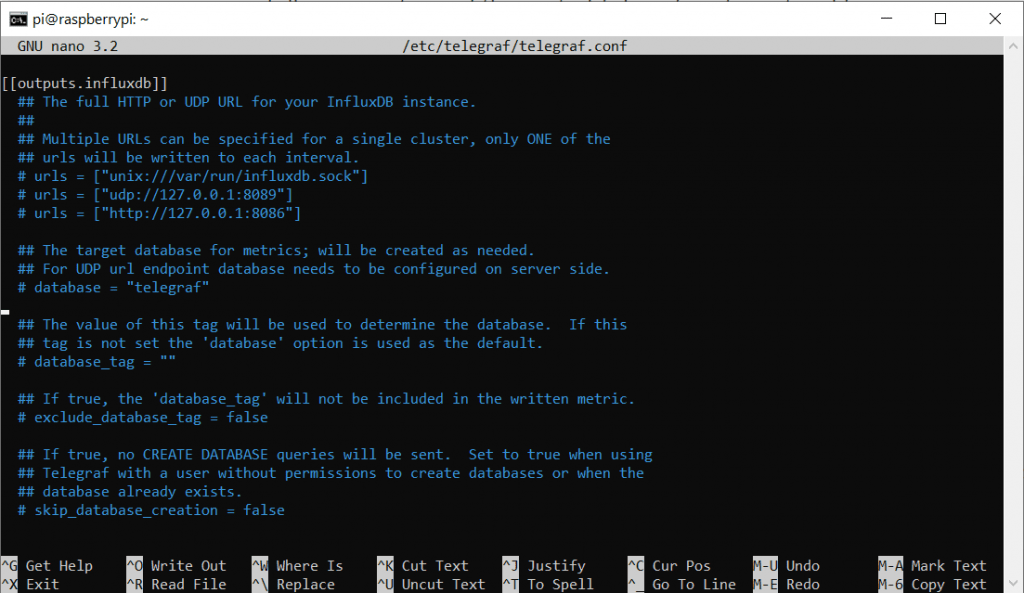
Nachher:
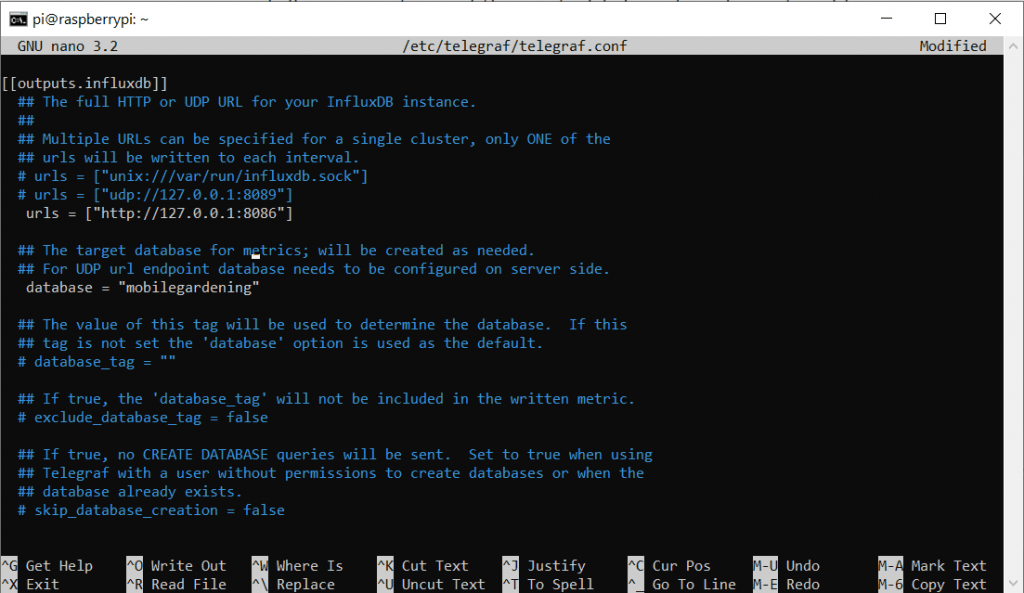
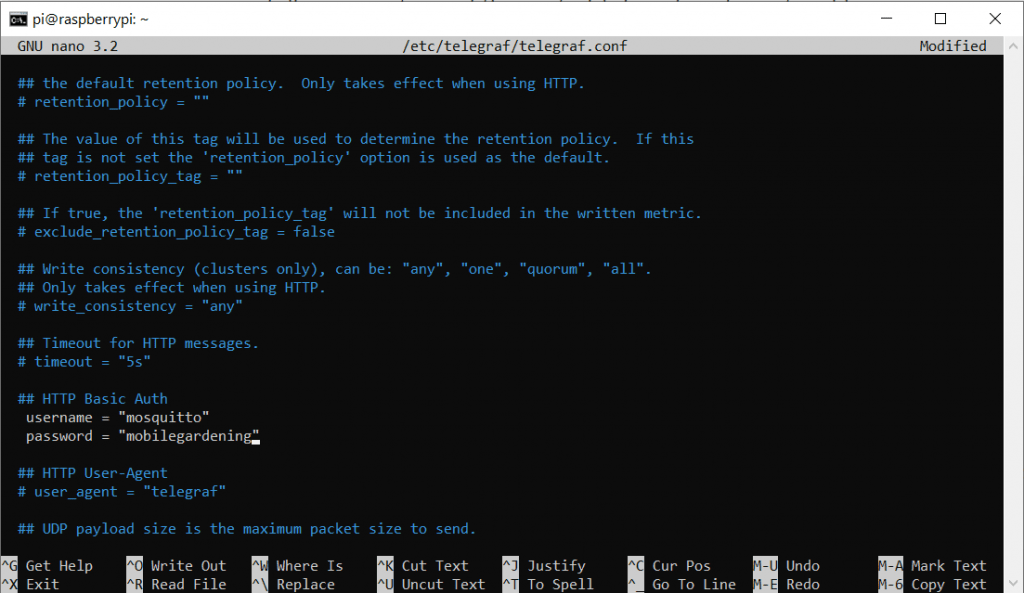
Da wir auf dem selben Gerät sowohl Broker als auch DB betreiben ist hier die IP 127.0.0.1 okay, da sie auf sich selbst verweist. Da wir die Ports auf den Standardeinstellungen belassen haben, sollte das so passen. Wir müssen nur die # Löschen um die Kommentierung aufzuheben. Natürlich müsst ihr die Daten entsprechend euren Log-In Daten anpassen.
urls = ["http://127.0.0.1:8086"]
database = "hivehealth"
username = "mqtt"
password = "hivehealth"Ganz weit unten in der Datei ist noch die Konfiguration für die Inputs. Mit Strg + W können wir aber gezielt nach MQTT suchen. Dort tragen wir folgendes ein, bzw. kommentieren es aus:
# Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
## MQTT broker URLs to be used. The format should be scheme://host:port,
## schema can be tcp, ssl, or ws.
servers = ["tcp://localhost:1883"]
## Topics to subscribe to
topics = ["stat/hiveWeight",
"stat/hiveHumidity",
"stat/hiveTemperature",
]
## Pin mqtt_consumer to specific data format
data_format = "value"
data_type = "float"
# ## If unset, a random client ID will be generated. client_id = "telegraf" # # ## Username and password to connect MQTT server. username = "mqtt" password = "password" Wir sagen Telegraf so, das wir einen MQTT-Consumer möchten, der sich auf localhost und Port 1883 mit den Log-In Daten an den MQTT-Broker hängt und auf die angegebenen Topics lauschen soll. Diese speichert er in die InfluxDB.
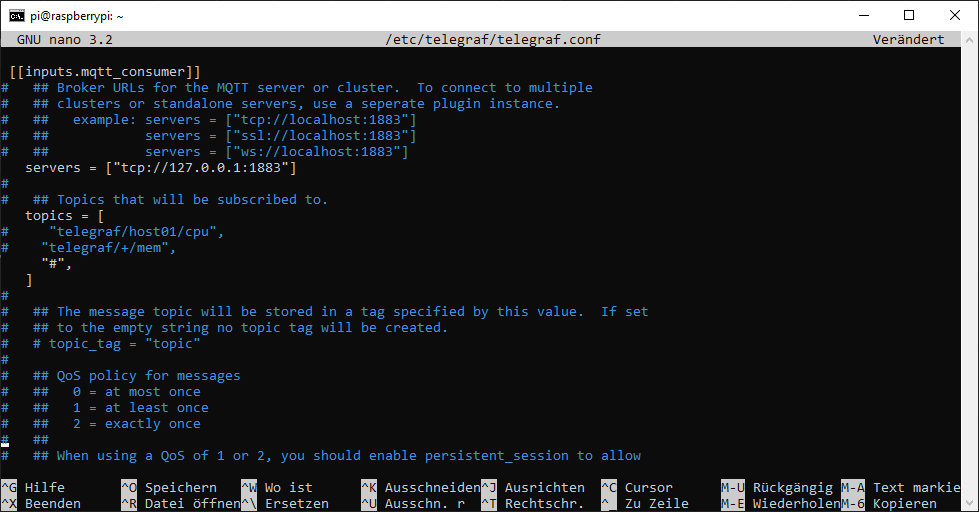
Die Änderungen speichern wir wieder mit Strg + O und Enter und verlassen Nano mit Strg + X.
Wir müssen den Prozess einmal neu Starten, damit die neue Konfiguration berücksichtigt wird und können dann Prüfen ob es geklappt hat.
sudo systemctl reload telegraf
sudo systemctl status telegraf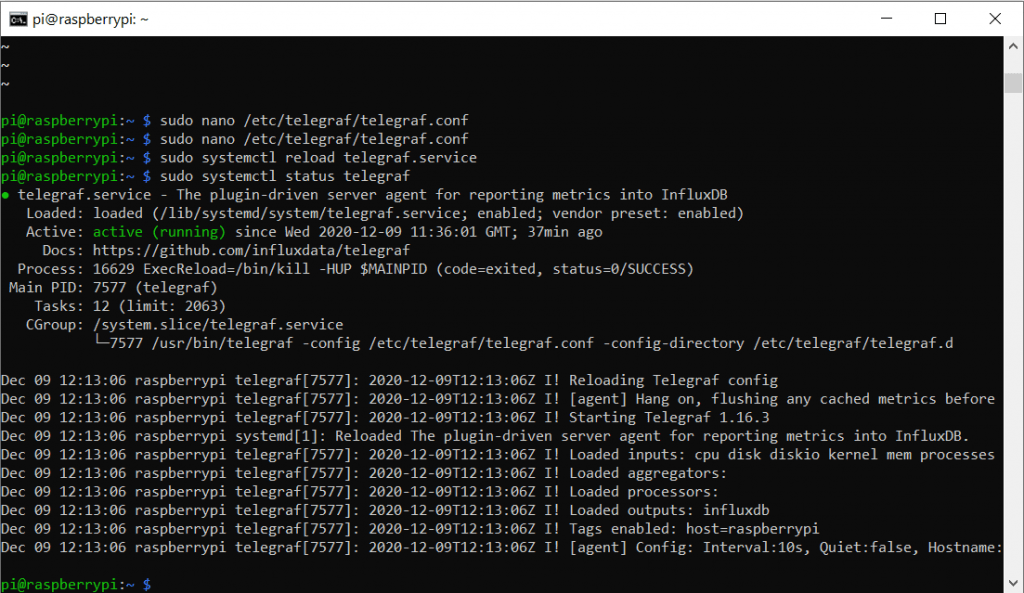
Mit Strg+C oder :q verlassen wir den Status-Monitor.
Test it again!
Standardmäßig überwacht Telegraf die Prozessorwerte und speichert diese nun in die Datenbank. Wenn wir also keine Fehler gemacht haben, können wir uns wieder in die InfluxDB einloggen und gucken ob es in unserer Datenbank die entsprechenden Einträge gibt.
influx
show databases
use hivehealth
show measurements
select * from mqtt_consumer limit 10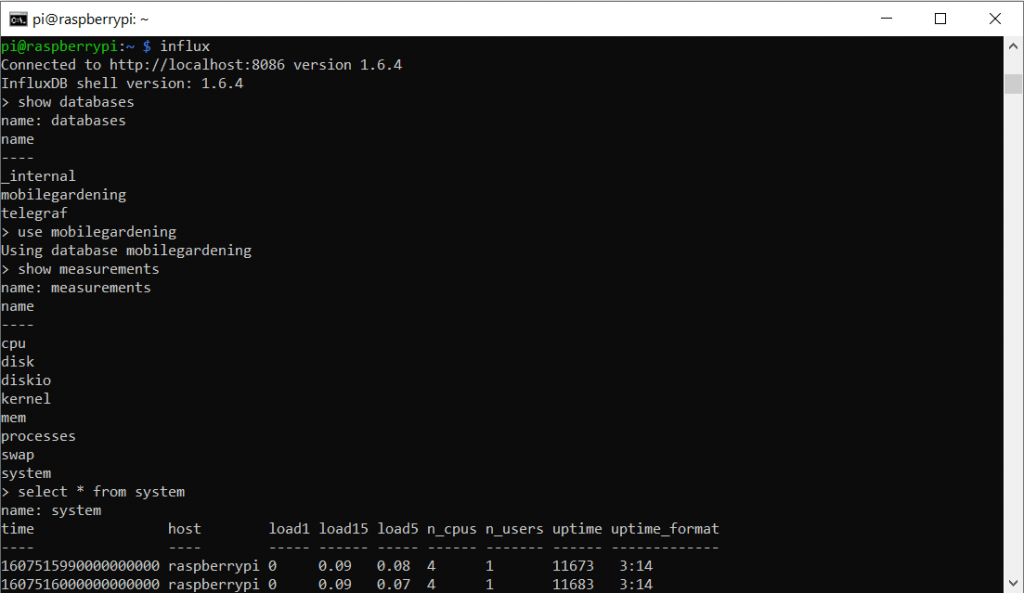
Wenn wir alles korrekt gemacht haben, sollte Telegraf das „Measurement“ mqqt_consumer angelegt haben. Dort werden die TagFields „host“, „topic“ und das KeyField „value“ angelegt.
Alternativ: Python 3 Bridge
Wer Fit mit Python ist, kann natürlich auch auf Telegraf verzichten und ein eigenes Script aufsetzten. Dazu brauchen wir aber ein paar Python3 dependencies. Zuerst installieren wir die Python 3 PIP Engine:
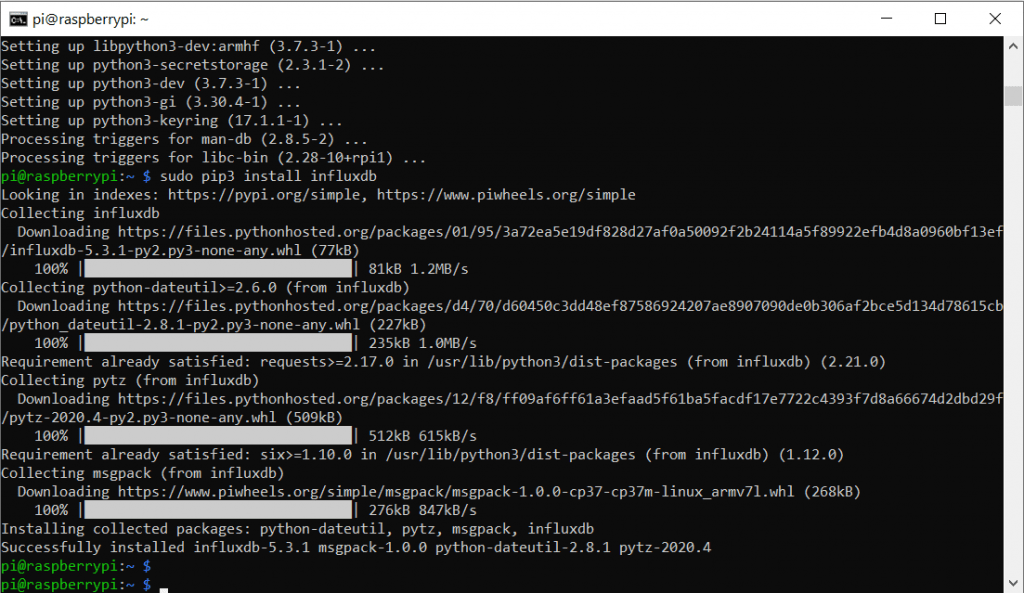
sudo apt-get install python3-pip -yDann das Paket paho-mqtt und influxdb
sudo pip3 install paho-mqtt
sudo pip3 install influxdb
Dann legen wir eine neue Datei an in der wir unser Script speichern:
sudo nano MQTTInfluxDBBridge.py
Das Script lautet wie folgt und muss nun in den Editor übertragen werden. Ändert natürlich entsprechend die IP und Log-In Daten ab:
import re
from typing import NamedTuple
import paho.mqtt.client as mqtt
from influxdb import InfluxDBClient
INFLUXDB_ADDRESS = '127.0.0.1'
INFLUXDB_USER = 'mqtt'
INFLUXDB_PASSWORD = 'hivehealth'
INFLUXDB_DATABASE = 'hivehealth'
MQTT_ADDRESS = '127.0.0.1'
MQTT_USER = 'hivehealth'
MQTT_PASSWORD = 'hivehealth'
MQTT_TOPIC = 'hive/+/+'
MQTT_REGEX = 'hive/([^/]+)/([^/]+)'
MQTT_CLIENT_ID = 'MQTTInfluxDBBridge'
influxdb_client = InfluxDBClient(INFLUXDB_ADDRESS, 8086, INFLUXDB_USER, INFLUXDB_PASSWORD, None)
class SensorData(NamedTuple):
location: str
measurement: str
value: float
def on_connect(client, userdata, flags, rc):
""" The callback for when the client receives a CONNACK response from the server."""
print('Connected with result code ' + str(rc))
client.subscribe(MQTT_TOPIC)
def _parse_mqtt_message(topic, payload):
match = re.match(MQTT_REGEX, topic)
if match:
location = match.group(1)
measurement = match.group(2)
if measurement == 'status':
return None
return SensorData(location, measurement, float(payload))
else:
return None
def _send_sensor_data_to_influxdb(sensor_data):
json_body = [
{
'measurement': sensor_data.measurement,
'tags': {
'location': sensor_data.location
},
'fields': {
'value': sensor_data.value
}
}
]
influxdb_client.write_points(json_body)
def on_message(client, userdata, msg):
"""The callback for when a PUBLISH message is received from the server."""
print(msg.topic + ' ' + str(msg.payload))
sensor_data = _parse_mqtt_message(msg.topic, msg.payload.decode('utf-8'))
if sensor_data is not None:
_send_sensor_data_to_influxdb(sensor_data)
def _init_influxdb_database():
databases = influxdb_client.get_list_database()
if len(list(filter(lambda x: x['name'] == INFLUXDB_DATABASE, databases))) == 0:
influxdb_client.create_database(INFLUXDB_DATABASE)
influxdb_client.switch_database(INFLUXDB_DATABASE)
def main():
_init_influxdb_database()
mqtt_client = mqtt.Client(MQTT_CLIENT_ID)
mqtt_client.username_pw_set(MQTT_USER, MQTT_PASSWORD)
mqtt_client.on_connect = on_connect
mqtt_client.on_message = on_message
mqtt_client.connect(MQTT_ADDRESS, 1883)
mqtt_client.loop_forever()
if __name__ == '__main__':
print('MQTT to InfluxDB bridge')
main()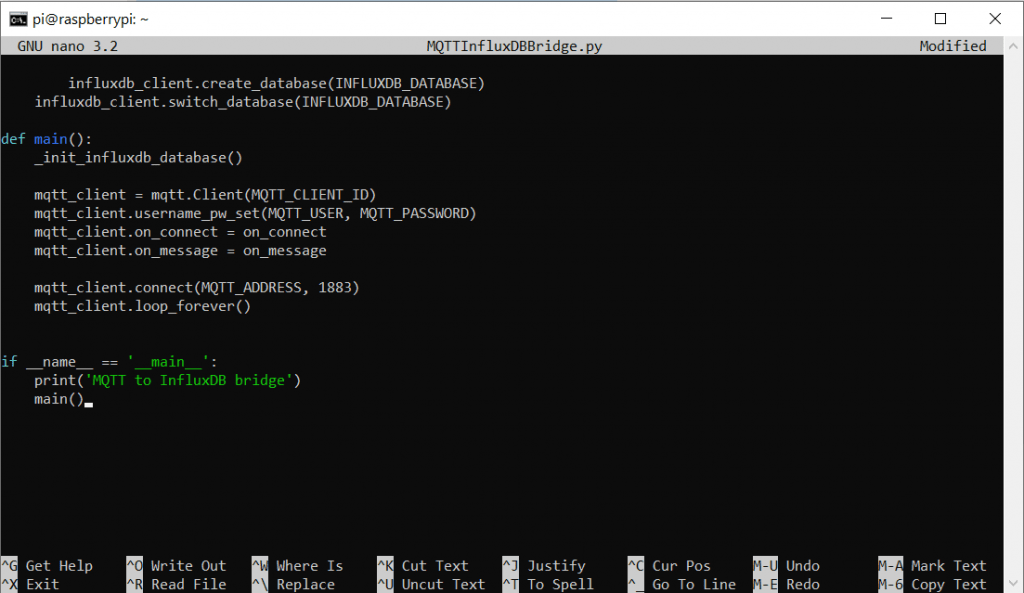
Natürlich muss man hier explizit die Topic-Struktur beachten. Mit Telegraf ist man da etwas flexibler. Das Script muss natürlich bei Systemstart mit gestartet werden. Dazu brauchen wir ein kleines Helferscript:
nano bridgelauncher.shIn das wir folgenden Code schreiben:
#!/bin/sh
# bridgelauncher.sh
sleep 60
cd /
cd home/pi
sudo python3 MQTTInfluxDBBridge.py
cd /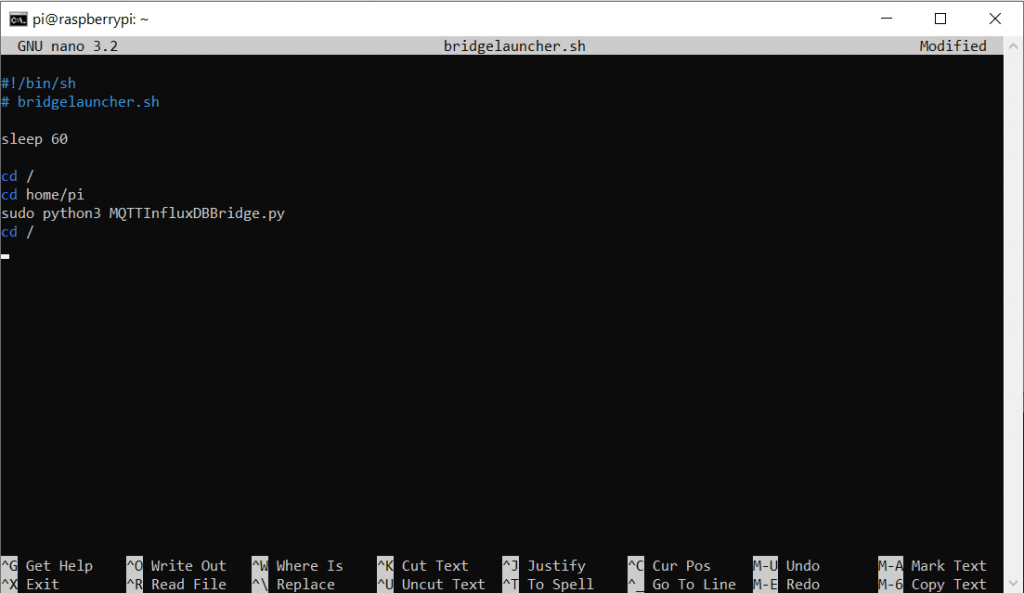
Speichern mit Strg + O und Enter und verlassen den Editor mit Strg +X.
Das Script kann man ausführbar machen mit dem Befehl:
chmod 755 bridgelauncher.shGrafana
Für Grafana müssen wir erneut eine externe Paketquelle in unsere Paketliste aufnehmen. Wir führen also die folgenden Befehle hintereinander aus:
curl -sL https://packages.grafana.com/gpg.key | sudo apt-key add -
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
sudo apt-get update
sudo apt-get install grafana -y
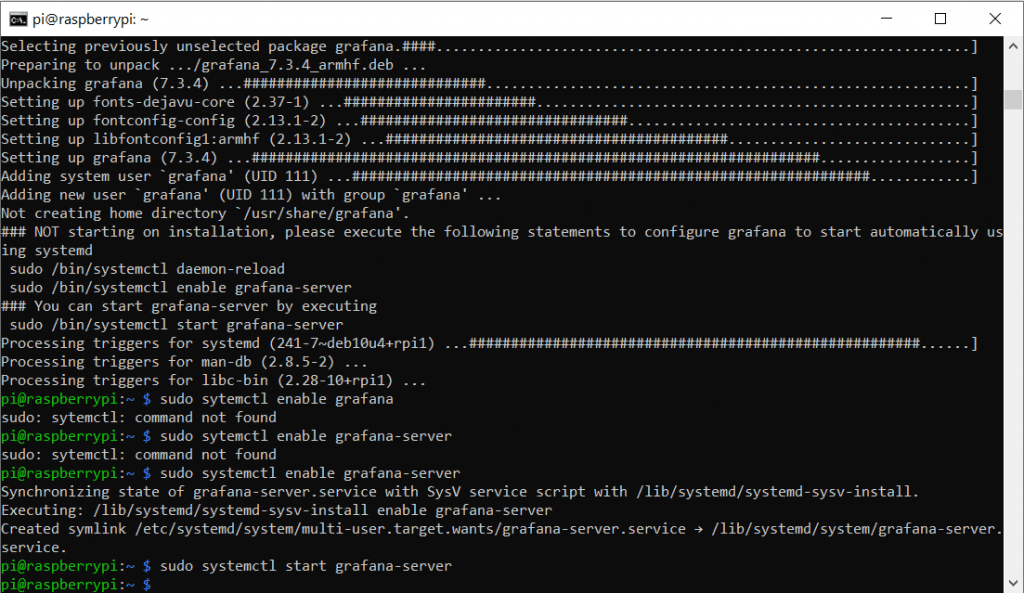
sudo systemctl start grafana-server
sudo systemctl enable grafana-server
sudo systemctl status grafana-server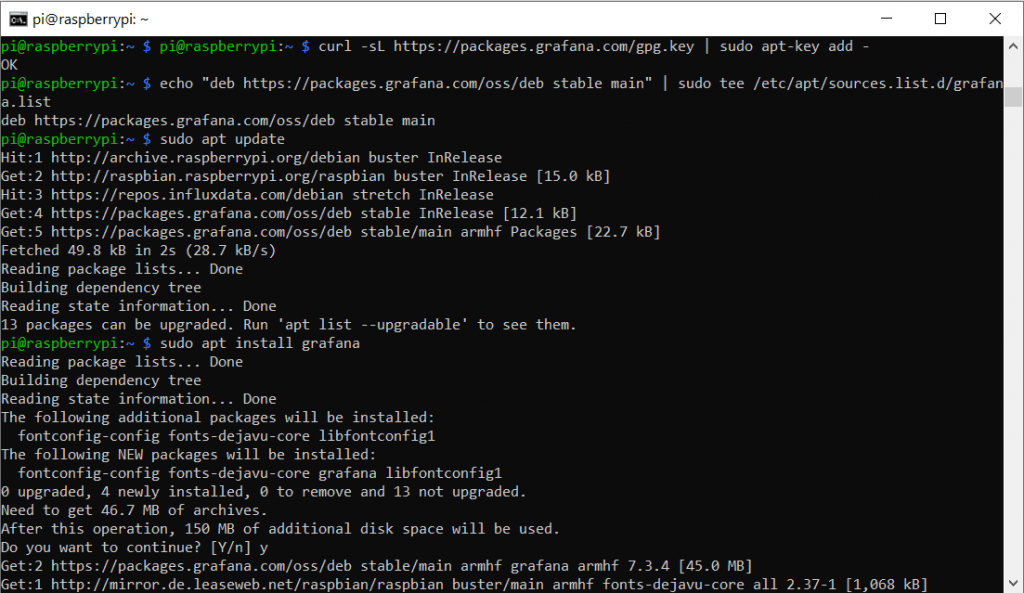
Jetzt können wir schon auf die Grafana-Weboberfläche wechseln. Wir öffnen einen neuen Tab im Browser und tippen unsere IP sowie den Port 3000 ein:
http://192.168.0.xxx:3000/Dort wählen wir uns mit der Kombination admin / admin (User & Kennwort) ein und werden gebeten ein neues Passwort zu vergeben.
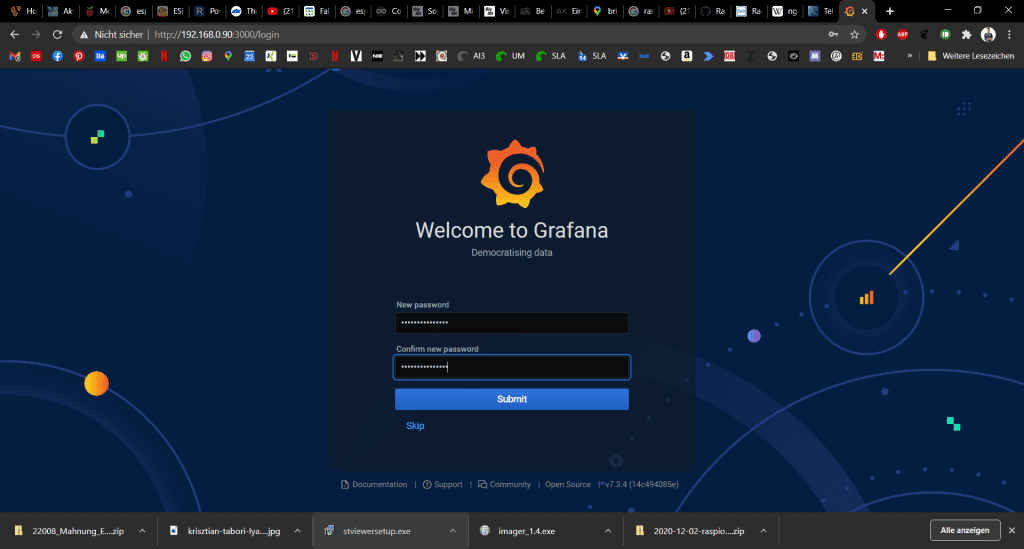
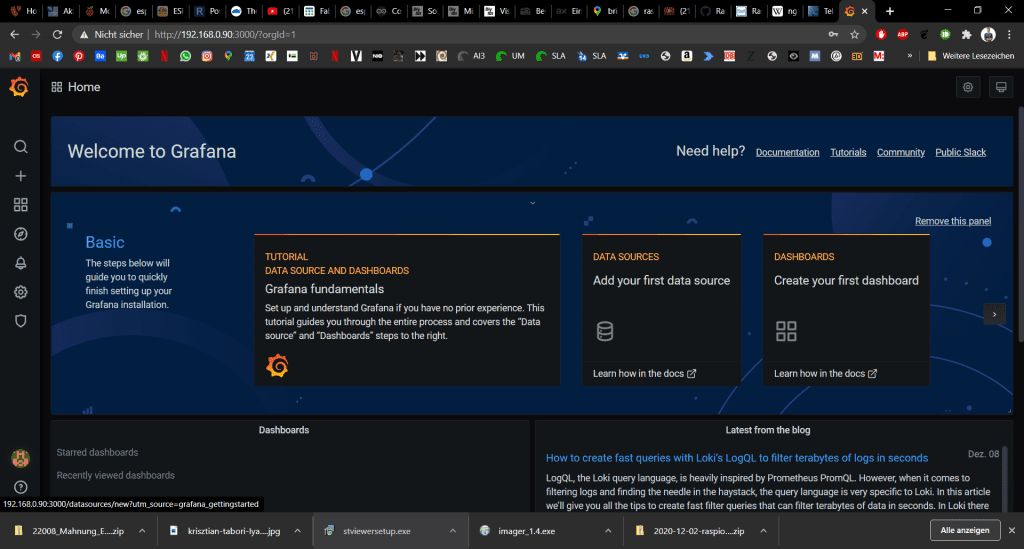
Zunächst müssen wir eine Datenquelle einfügen. Dazu gibt es einen großen Button auf der Startseite.
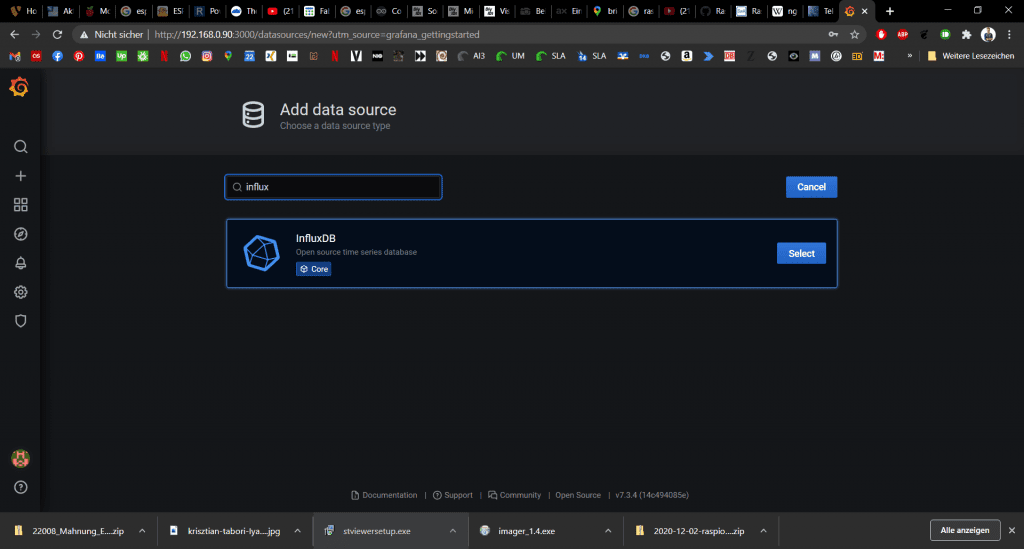
Im Suchfeld geben wir einfach Influx ein und finden das entsprechende Plug-In
Hier können wir wieder localhost nutzen, da in diesem Beispiel alles auf dem selben RaspberryPi läuft.
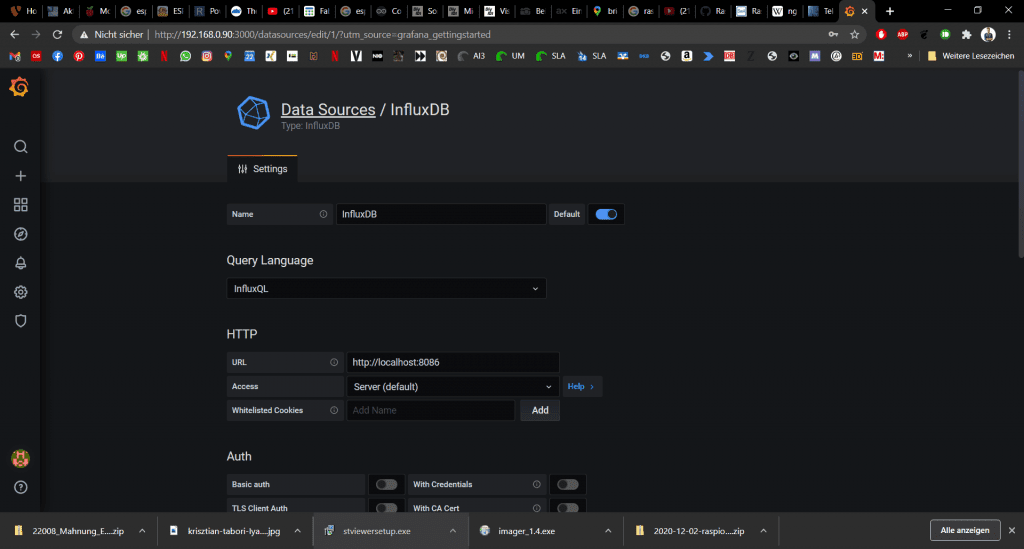
Weiter unten müssen wir noch unsere Datebank, User und Kennwort eingeben. Dann klicken wir auf Save & Test. Wenn alles in Ordnung ist bekommen wir die folgende Rückmeldung:
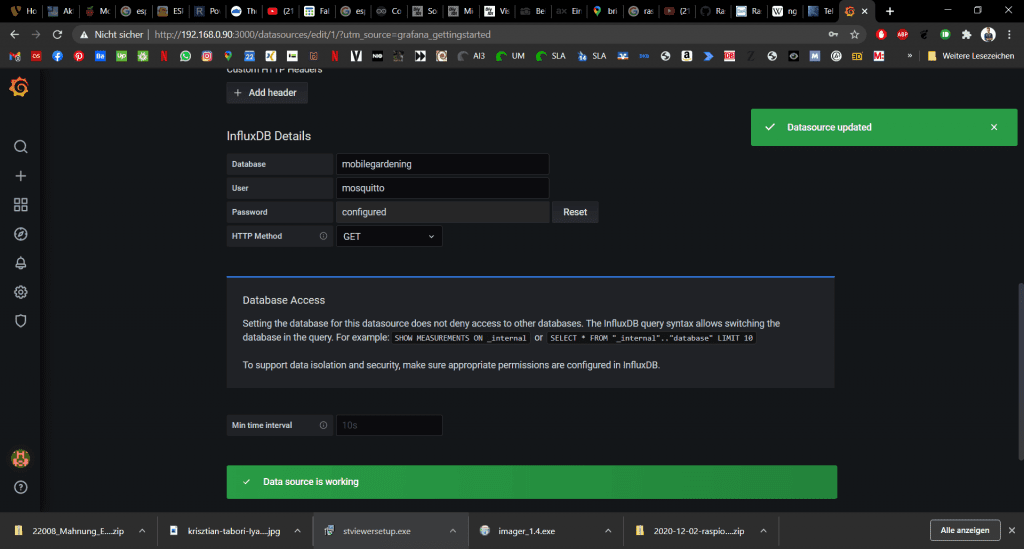
Dashboards
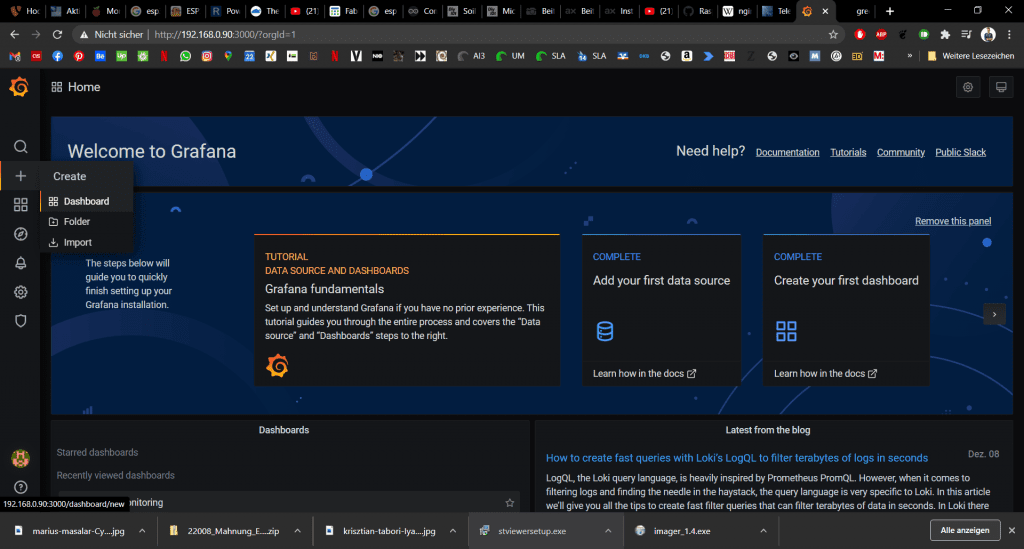
Nun können wir uns Schicke Dashboards für unsere Sensordaten anlegen. Dazu klicken wir auf das große Plus Icon links und wählen Dashboard aus:
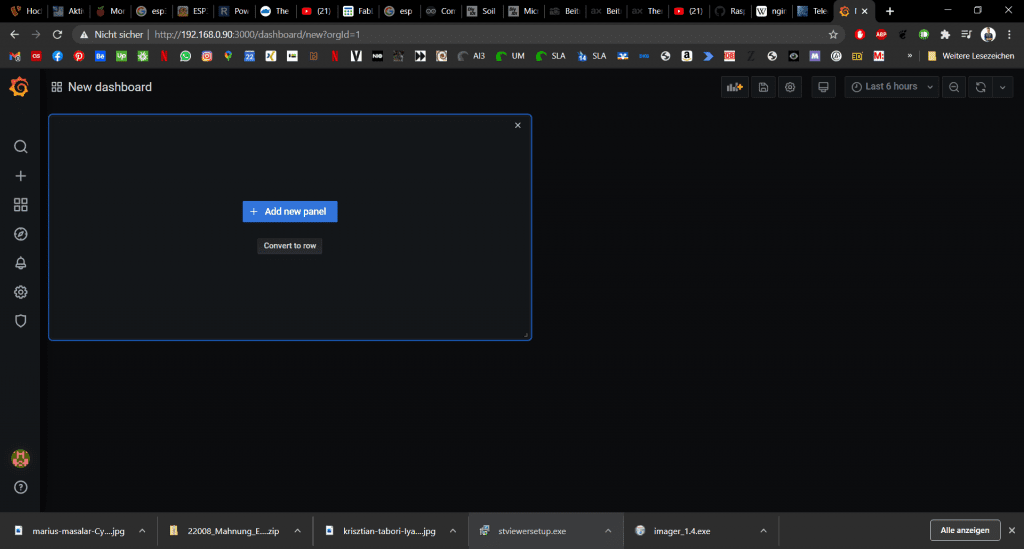
Danach können wir auf Add new Panel klicken:
Später nutzen wir für das erstellen weiterer Panels den Button ganz links in der Icon-Leiste oben rechts.
Nun können wir eine der Datenreihen wählen und das Panel entsprechend benennen. Es gibt aber noch viele viele weitere Möglichkeiten Dashboards zu gestalten. Dazu findet man auch viel im Netz. Wichtig ist hier noch der Faktor „where“, da die Datenreihe des sensors mqtt_consumer heißt. Mehr zur Struktur in InfluxDB gibt es <hier/>
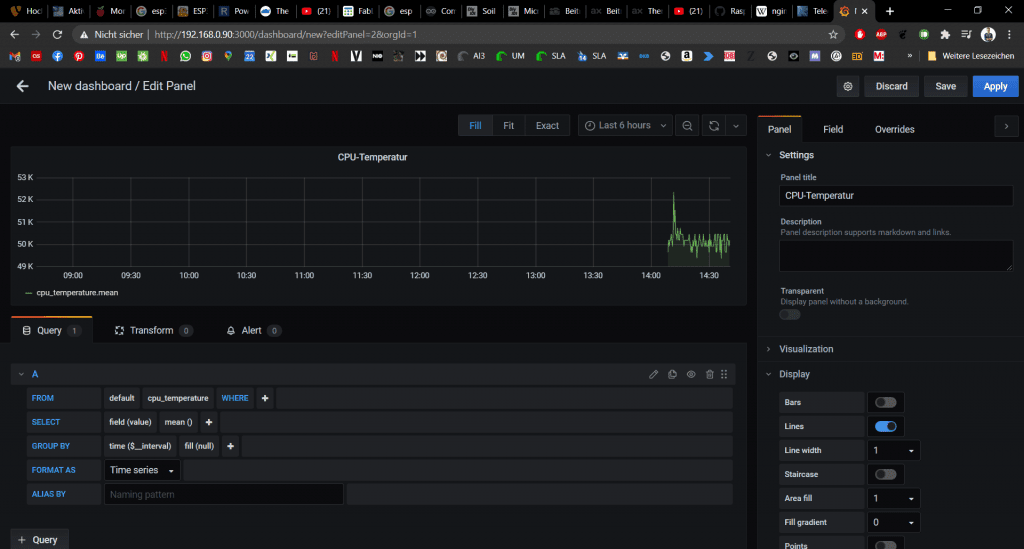
Nun können wir uns für unsere Bienenstockwaage ein komplettes Dashboard gestalten.
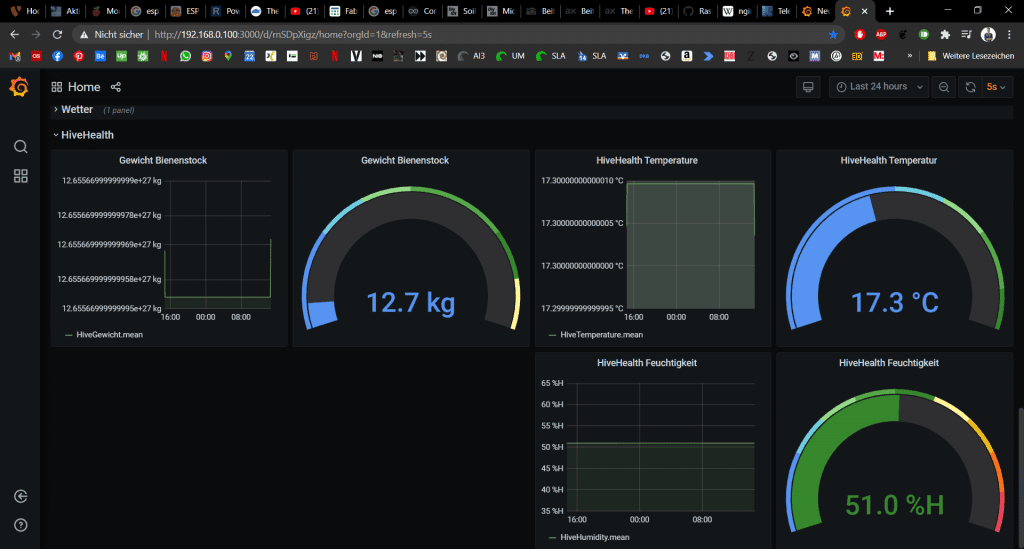
Zugriff aus dem Internet (Achtung – Unvollständig)
Damit wir aus dem Internet auch mit ruhigem Gewissen und sicher auf unseren IOT-Server zugreifen können, setzen wir einen Webserver ein. Hierzu können wir ein Let’s Encrypt Zertifikakt (kostenlos) an uns selbst ausstellen um eine verschlüsselte SSL Verbindung zu nutzen. Da sich die IP für uns täglich ändert, brauchen wir außerdem einen DNS Dienstleister, der diese auf eine Domain (Webadresse) zeigt.
NginX
Als Webserver nutzen wir NginX (gesprochen Engine X).
sudo apt-get install nginxWenn wir nun auf die IP und Port 80 gehen sollten wir die NginX Willkommensnachricht sehen.
http://192.168.0.xxx:80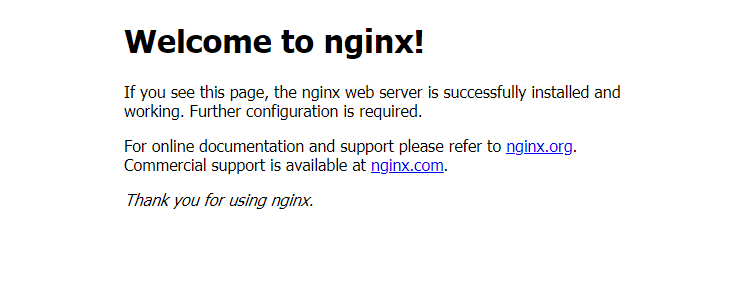
Außerdem wollen wir NginX auch bei Systemstart starten:
sudo systemctl enable nginxWir legen uns für unsere Website einen Ordner an:
sudo mkdir /var/www/hivehealthsudo nano /etc/nginx/conf.d/mobilegardening.confcertbot
Danach installieren wir certbot. Dies ist ein praktischer Service, der automatisiert jeden Monat unser Zertifikat erneuert.
sudo apt-get install certbot
TBA
Alternativer Server: Synology Diskstation & Docker (Achtung: hier Unvollständig)
In diesem Guide arbeite ich auf einer Synology Disk Station. Ich setze einfach mal voraus, dass euer System bereits läuft. Als erstes öffnen wir das Paketzentrum und geben im Suchfeld „docker“ ein und installieren das Paket. Nachdem es erfolgreich Installiert ist, könnt ihr den Button Öffnen drücken. Später ist es über die App-Liste (Button oben Links) erreichbar.
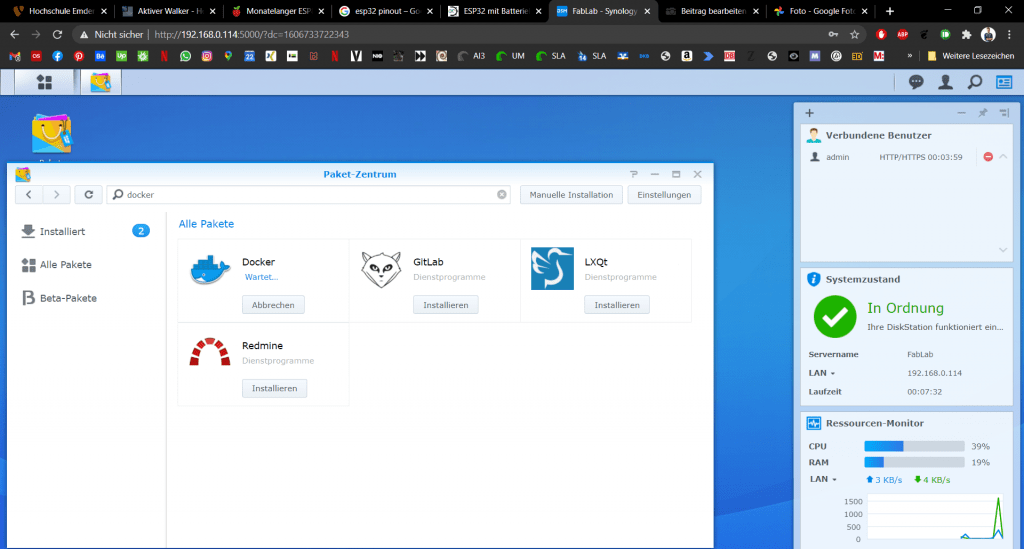
Zunächst kommt im Docker-Fenster eine Meldung, die wir gerne kurz lesen können oder einfach ignorieren. Danach könnt ihr Links auf den Reiter „Registrierung“ klicken und nach und nach die vier Images herunterladen.
- mosquitto
- telegraf
- influxdb
- grafana
Diese findet man jeweils leicht über das Suchfeld. Es gibt auch gemischte Images, die für bestimmte Zwecke vor konfiguriert sind. Die offiziellen Images haben ein Symbol hinter dem Namen. Fangen wir mit mosquitto an.
Mosquitto
Damit wir Mosquitto leichter konfigurieren können, empfielt es sich, den Nano-Editor zu installieren. So könnt ihr, wie ihr es z.B. vom Raspi gewöhnt seit, Dateien editieren. Dazu gehen wir im Paket-Zentrum auf Einstellungen (Button ist oben Rechts) und fügen unter dem Reiter Paketquellen folgende URL hinzu:
http://packages.synocommunity.com/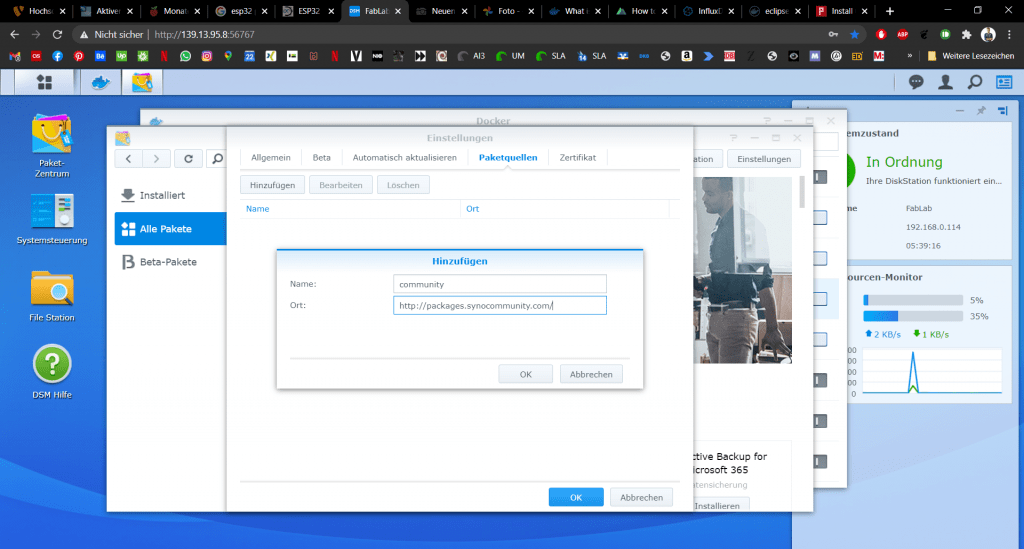
Ein neuer Reiter „Community“ erscheint. Wenn wir hier nun nach nano Suchen erscheint ein Paket, in welchem es integriert ist.
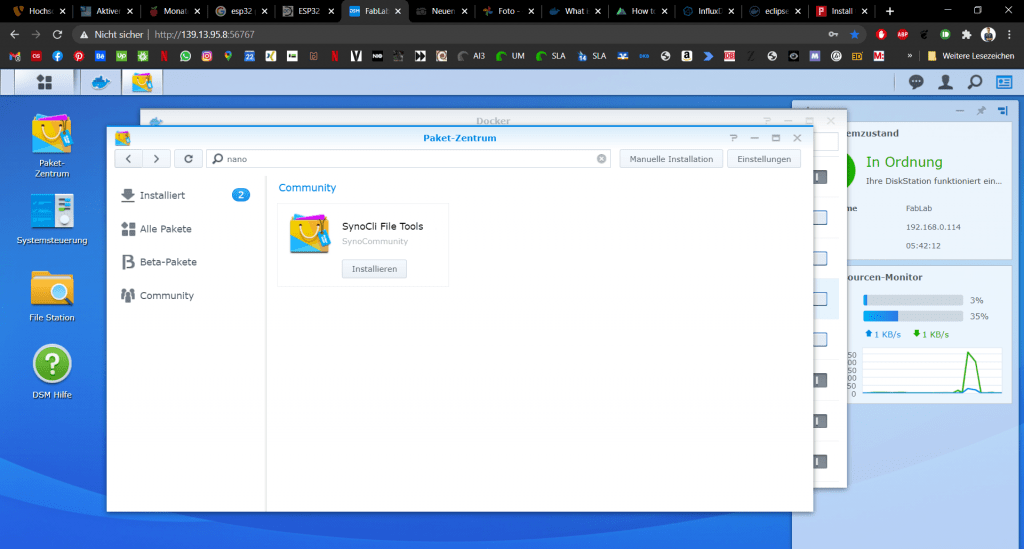
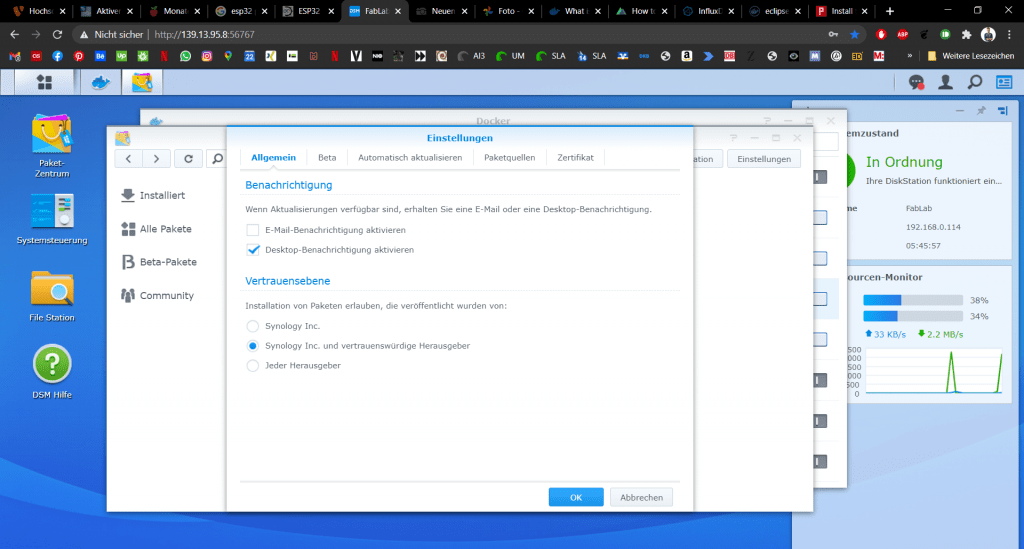
Falls sich das nicht direkt installieren lässt, müssen wir wieder in die Einstellungen gehen und fremde Paketquellen erlauben. Hier empfiehlt sich die Einstellung auf „Vertrauenswürde Herausgeber zu beschränken.
Wenn wir das Mosquitto Image habt, wechselt in den Reiter Abbild und wählt das mosquitto Image aus der Liste aus. Danach wird der Button „Starten“ klickbar. Ein neues Fenster öffnet sich, wir können aber alles auf den Standard Einstellungen belassen.
Nun sollte euer Mosquitto auf Port 1883 funken. Eigentlich könnten wir uns nun zufrieden geben, jedoch möchte ich den Broker mit Nutzernamen und Passwort sichern.
InfluxDB
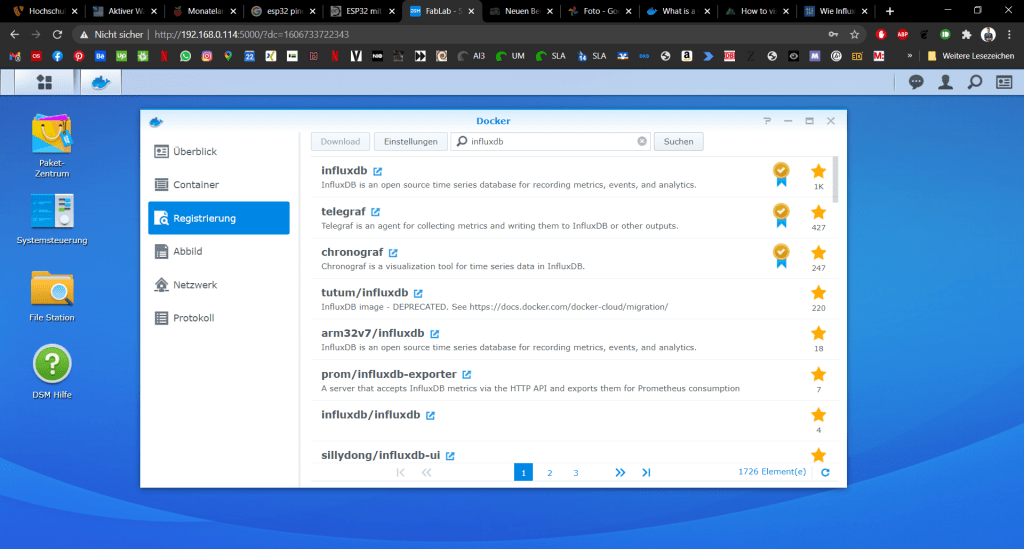
InfluxDB ist eine sogenannte Time-Series Database. In dieser legen wir unsere Sensorwerte und die Messzeitpunkte ab.
Wir laden das Image in dem wir auf das Feld mit dem Namen klicken und dann auf den Button „Download“ oben links. (Das UI von Synology ist etwas gewöhnungsbedürftig oder?)
Wenn das Image erfolgreich heruntergeladen wurde können wir auf den Reiter Abbild wechseln und wiederum das entsprechende Feld markieren und danach den Button Starten drücken.
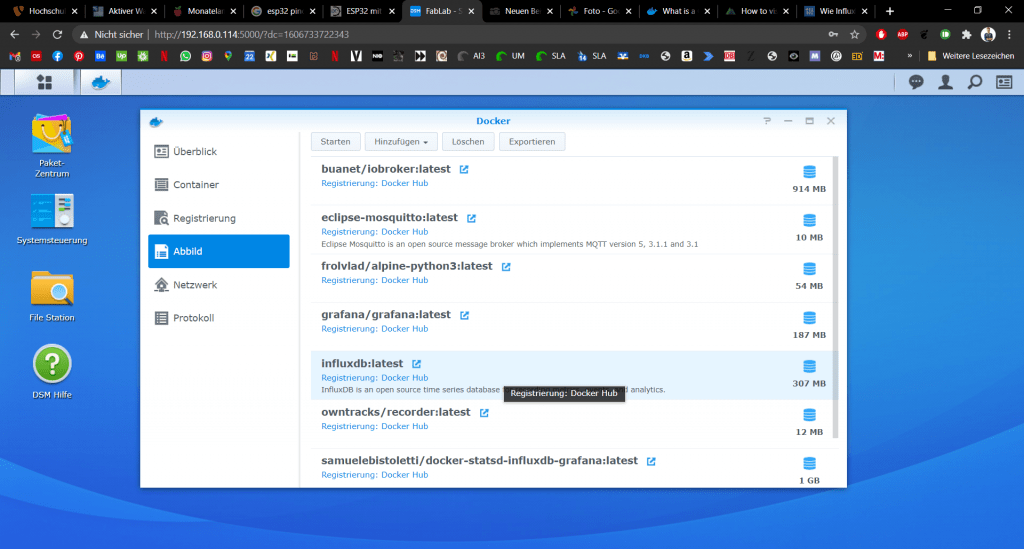
Es öffnet sich ein Wizard zur Einrichtung, wo wir einfach alles auf Standard-Einstellung lassen können.
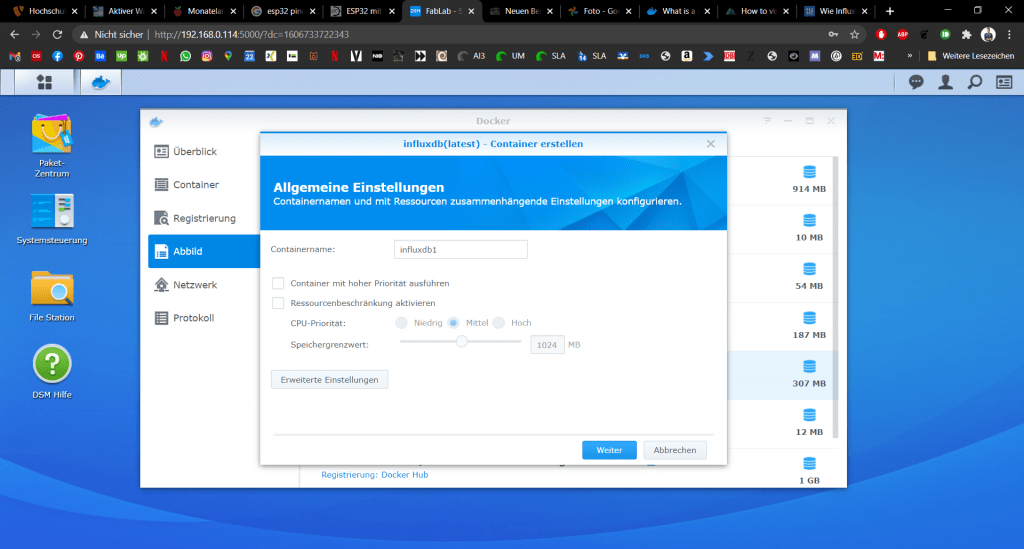
Danach wechseln wir in den Reiter Container. Hier sind alle aktiven Container gelistet. Wir können diese rechts über einen Button Starten und Stoppen. Wir möchten nun InfluxDB anwählen und dann in die Detailansicht wechseln. Dazu klicken wir oben wieder auf den entsprechenden Button.
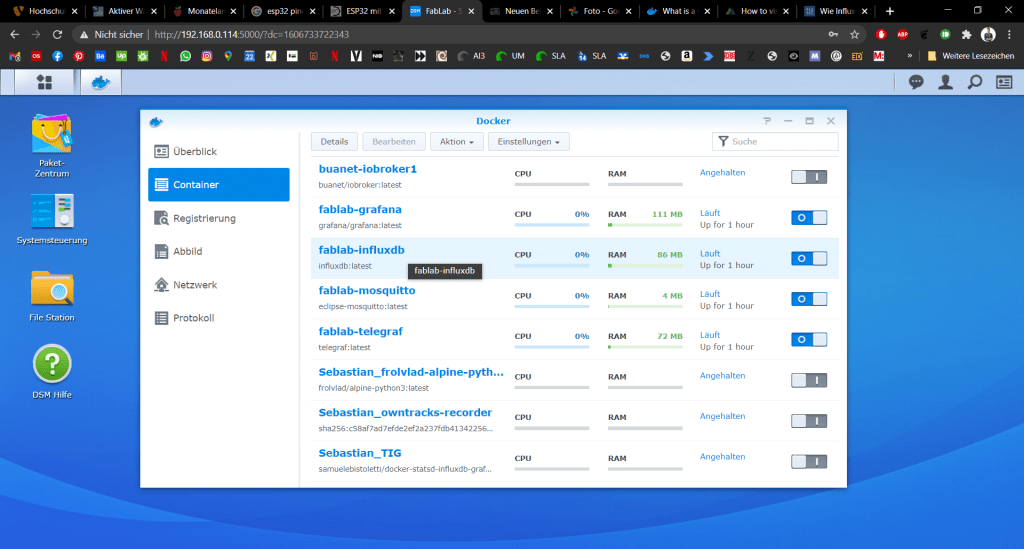
Im neuen Fenster wechseln wir auf den Reiter Terminal und klicken auf den Button „Erstellen“. In der Liste erscheint das Feld bash. Wir klicken darauf. Rechts in der Console sollte dann ein Text erscheinen.
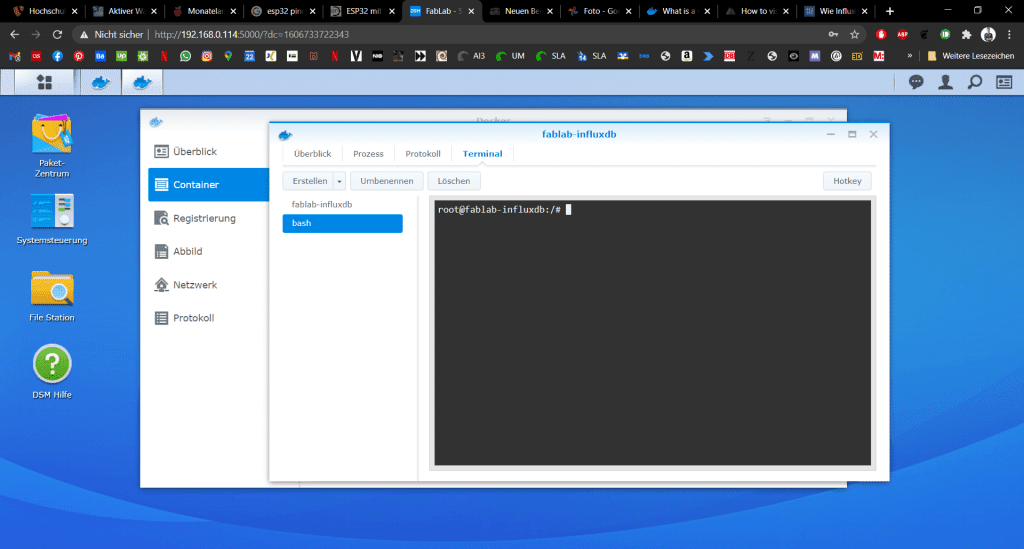
Hier tippen wir nun folgende Befehle ein, um unsere InfluxDB zu konfigurieren:
influxso gelangen wir in die CLI-Steuerung von InfluxDB. Dann legen wir eine neue Datenbank für unser Projekt an und wählen diese danach aus:
CREATE DATABASE hivehealth
USE hivehealthAls nächstes brauchen wir natürlich einen admin user mit entsprechendem Passwort. Das Passwort muss in einfache Anführungszeichen gesetzt werden. Außerdem möchten wir einen Nutzer für Grafana mit eingeschränkten Rechten (Nur Lesen). Und einen für Telegraf mit Schreibrechten.
CREATE USER admin WITH PASSWORD 'savepassword' WITH ALL PRIVILEGES
CREATE USER grafana WITH PASSWORD 'anothersavepassword'
GRANT READ ON hivehealth TO grafana
CREATE USER telegraf WITH PASSWORD 'guesswhat'
GRANT ALL ON hivehealth TO telegrafDann können wir überprüfen ob alles geklappt hat. Die jeweiligen Befehle sollten eine entsprechende Liste ausgeben.
show databasesshow usersWenn alles geklappt hat können wir influxDB verlassen:
exitDas wars auch schon. Weiter geht es mit:
Grafana
Troubleshooting
Natürlich kann es passieren, das einige Schritte hier nicht auf Anhieb so funktionieren. Hier sind ein paar mögliche Stolpersteine:
Firewall
Wenn ihr z.B. nicht per SSH auf euer System gelangt, liegt es ggf. an der Firewall. Wir können für alle oben aufgeführten Anwendungen ausnahmen definieren. Dazu gehen wir in die Systemsteuerung und unter dem Punkt Sicherheit wechseln wir in den Reiter Firewall. Dort können wir ein custom Profil erstellen und Regeln bearbeiten.
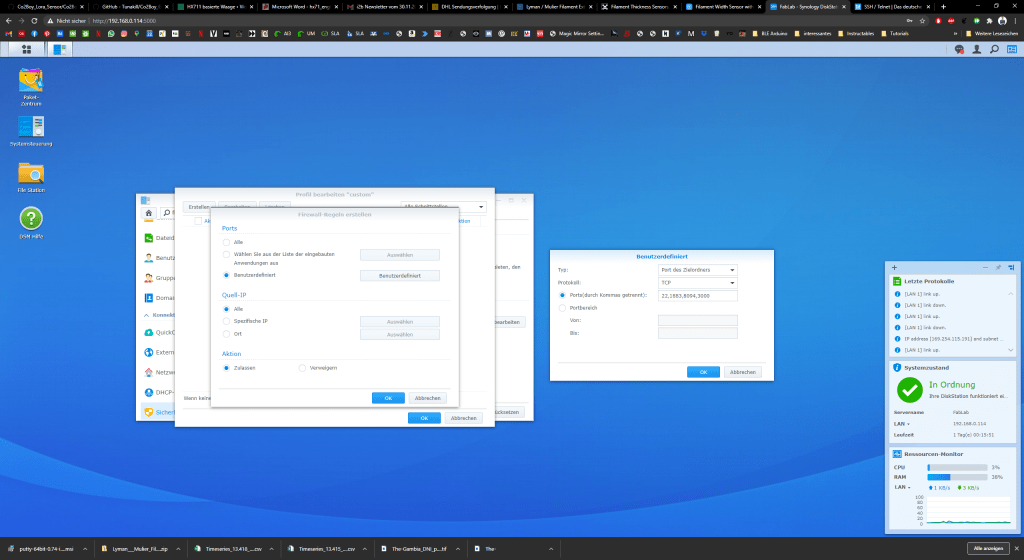
Wir sollten eine Ausnahme in der Firewall für alle Ports die wir für dieses Projekt brauchen einrichten.
- ssh: 22
- mqtt: 1883
- grafana: 3000
- ftp: 21
User
Falls es dann immer noch nicht klappt könnt ihr einen neuen User Anlegen und diesen der Administratorengruppe zuordnen.
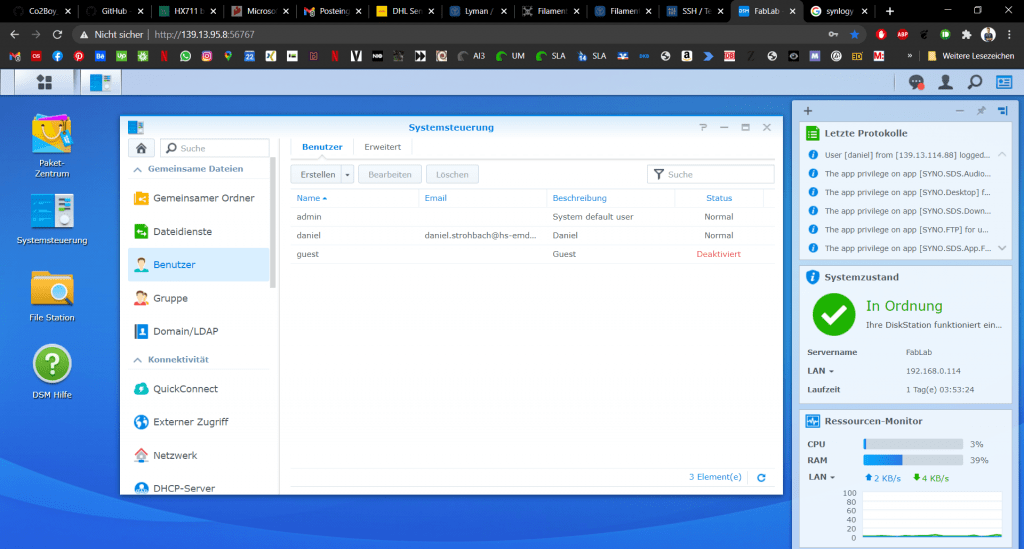
Summary
Sorry, hier ist alles etwas Lückenhaft geblieben, da das Projekt etwas eingeschlafen ist. Ich hoffe aber, der Teil, um euren eigenen Datalogger auf Basis des Raspi aufzubauen, und dabei ohne openHAB oder Homeassistant auszukommen, ist hilfreich.
$ Die mit einem $ gekennzeichneten Links, sind Affiliate Links. Wenn du über diese in den Shop gelangst und etwas kaufst, bekomme ich eine kleine Provision


1 Kommentar
[…] kein openHAB / HomeAssistant will oder hat, aber noch einen RaspberryPi herumfliegen hat, kann <hier/> den Guide für einen IOT Server auf Basis des RaspberryPi […]